Columnar vs Row based
Columnar vs Row based
Apache Parquet is a popular columnar storage format optimized for fast data retrieval and used in analytics applications on the AWS platform. Parquet and other popular columnar storage formats have three main benefits that make them suitable for use with Athena;
- Ability to compress data by column, thereby helping query speed faster, storage costs, and query execution costs lower.
- The skip data blocks feature allows Athena queries to fetch only the necessary data blocks thereby improving query performance.
- Splitting data allows Athena to divide data reading among multiple Athena readers and increase parallel processing during query processing.
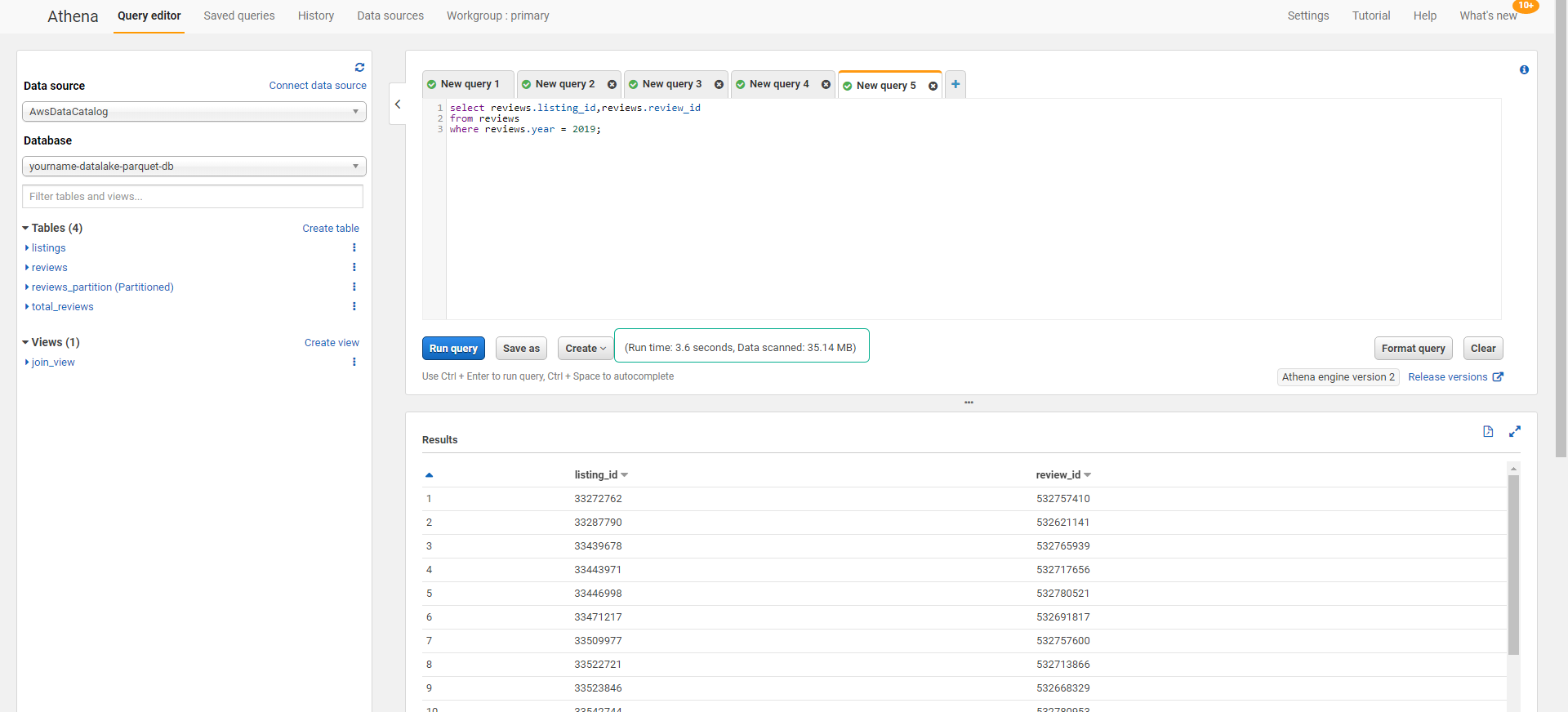
- Click to select database yourname-datalake-parquet-db. (Data in Columnar - Parquet format)
- Execute the query below.
select reviews.listing_id,reviews.review_id
from reviews
where reviews.year = 2019;
- Click to select database yourname-datalake-db. (Data in Row base format - CSV)
- Execute the query below.
select reviews.listing_id,reviews.review_id
from reviews
where reviews.year = 2019;
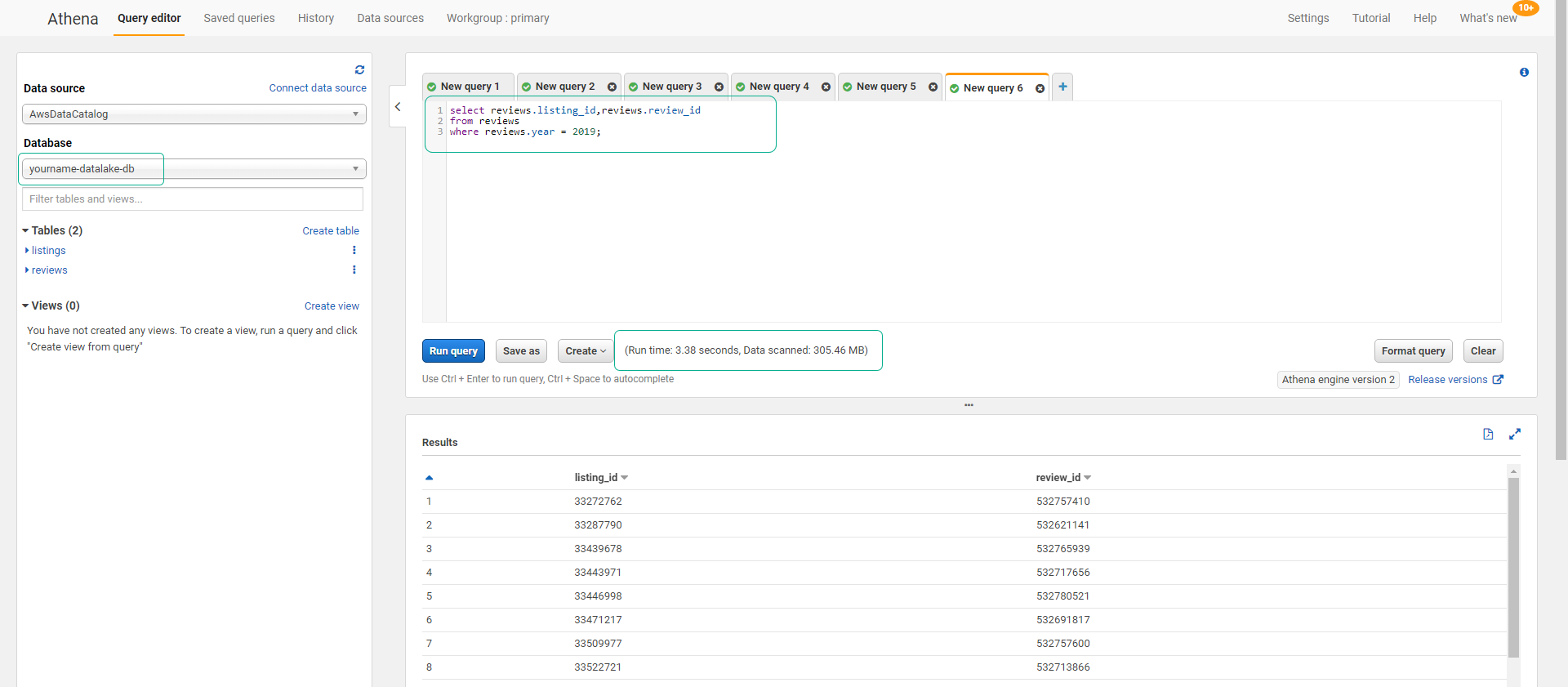
We can compare the amount of scanned data in the two cases. In the case of using CSV, we will have to pay the cost of scanning data 10 times more.