Data Profiling
Data Profiling
When working on a project, DataBrew displays statistics such as the number of rows in the dataset and the distribution of unique values in each column. These statistics, and many more, represent a profile of the sample. When you run a data profile job, DataBrew creates a report called a data profile. You can create a data profile for any dataset by running a data profile job.
-
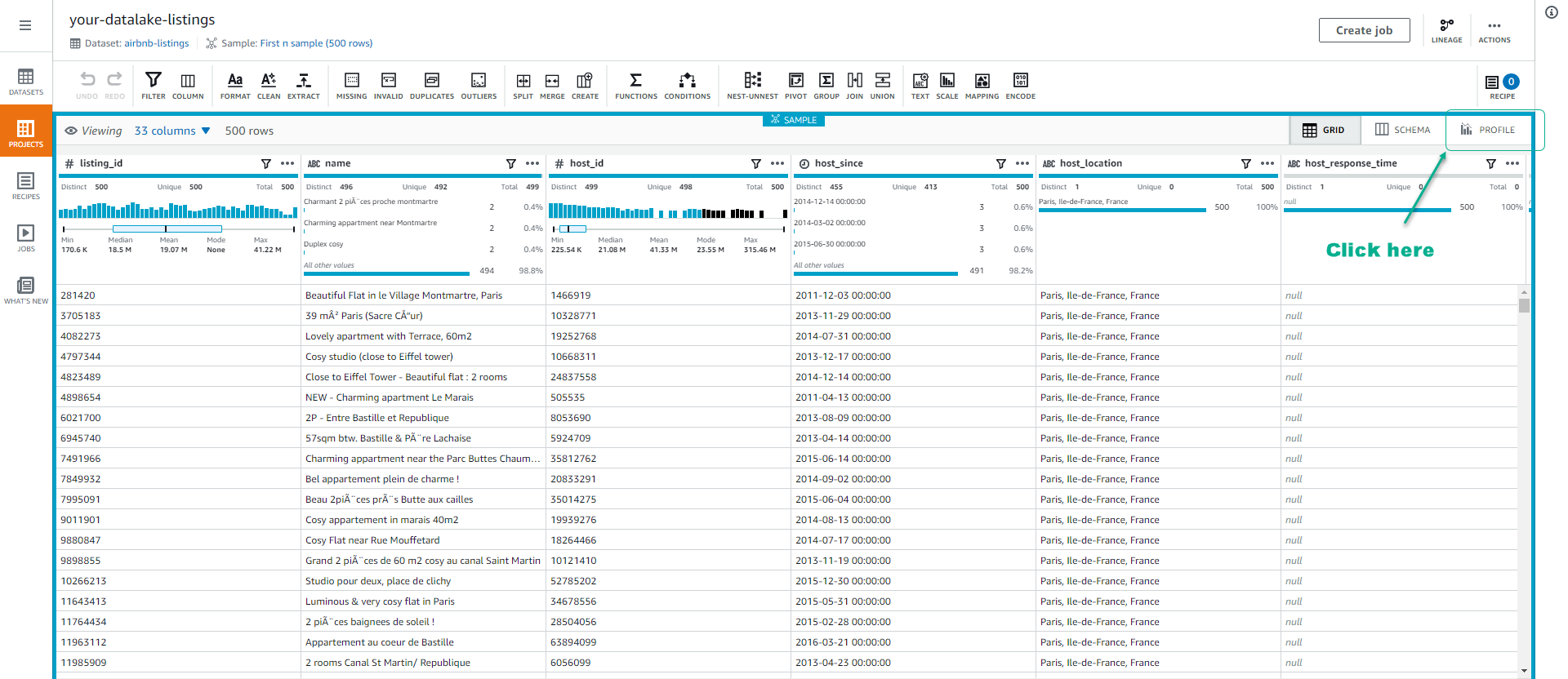
Click on the Profile tab in the Projects interface.
-
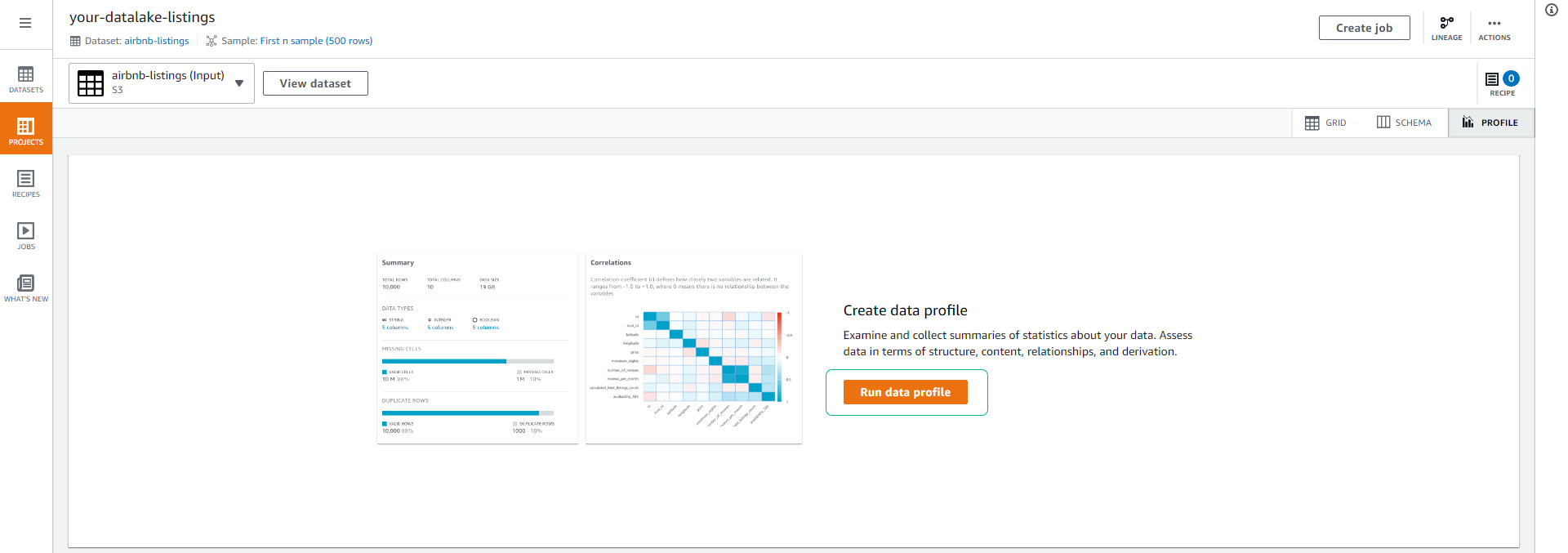
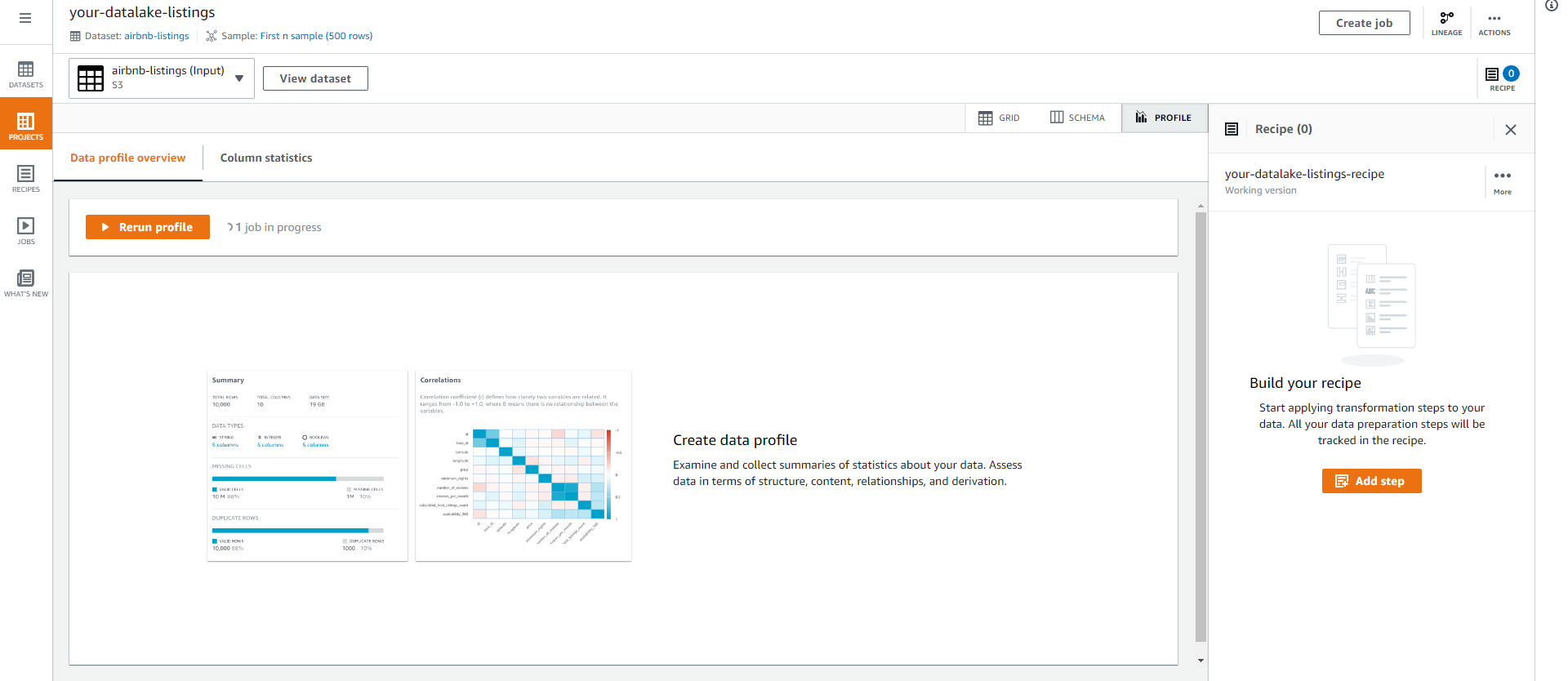
Click Run data profile.
-
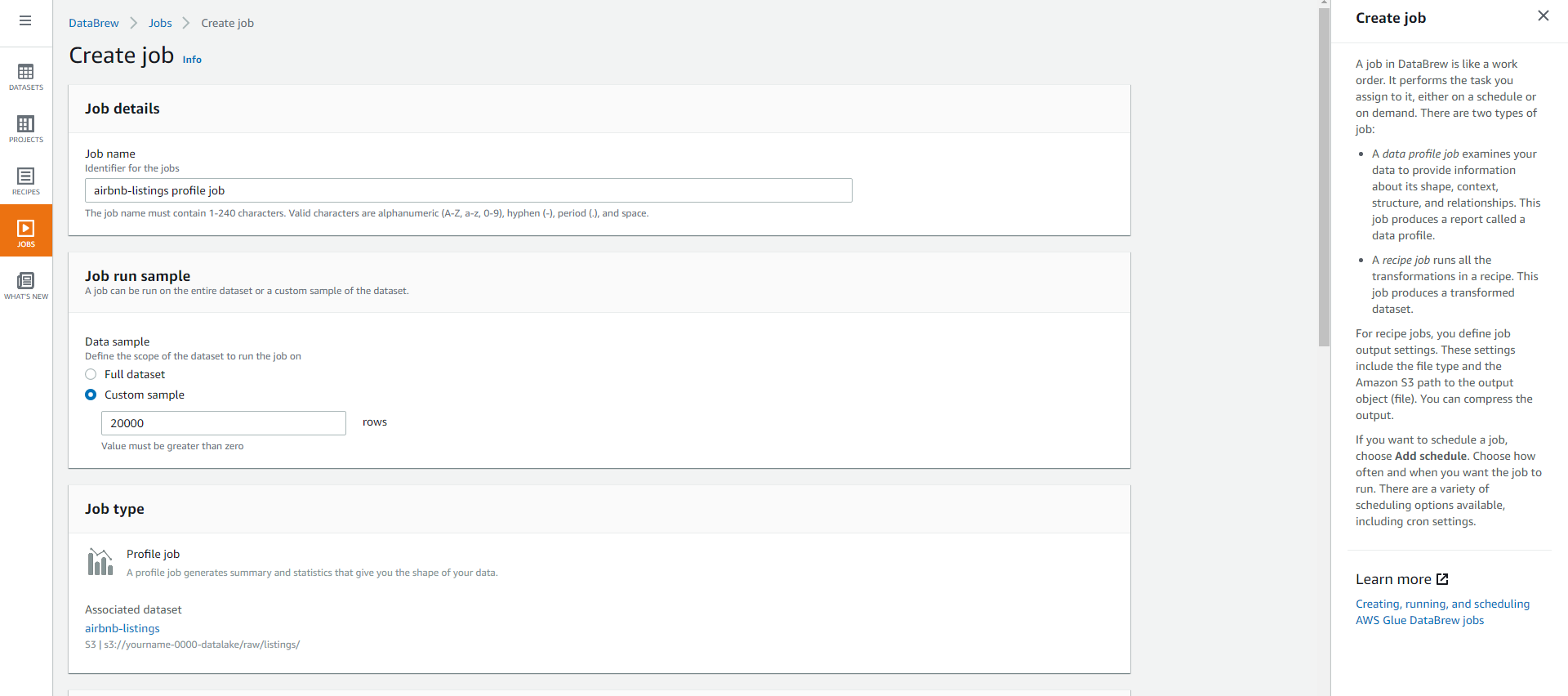
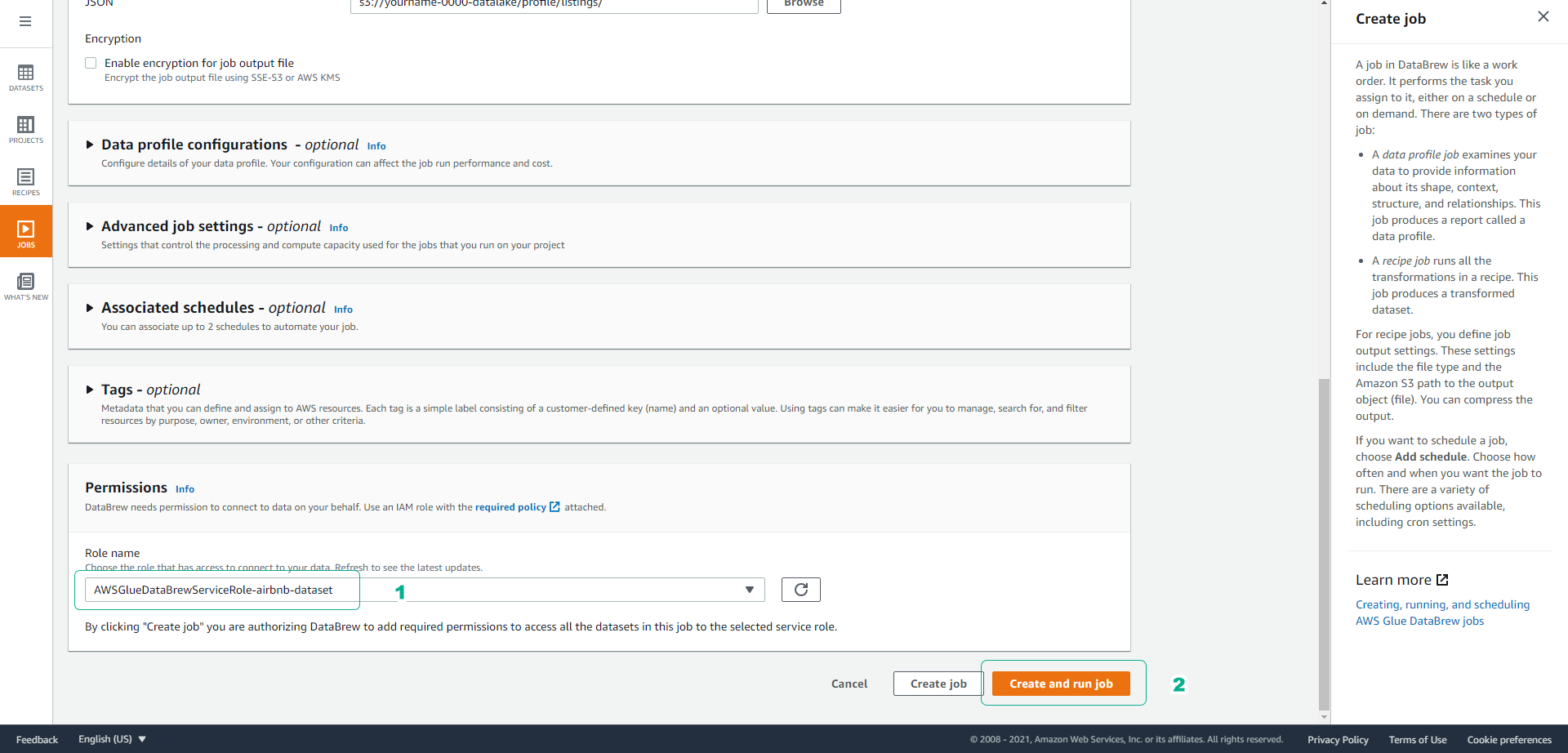
On the Create job page, keep the default name settings.
-
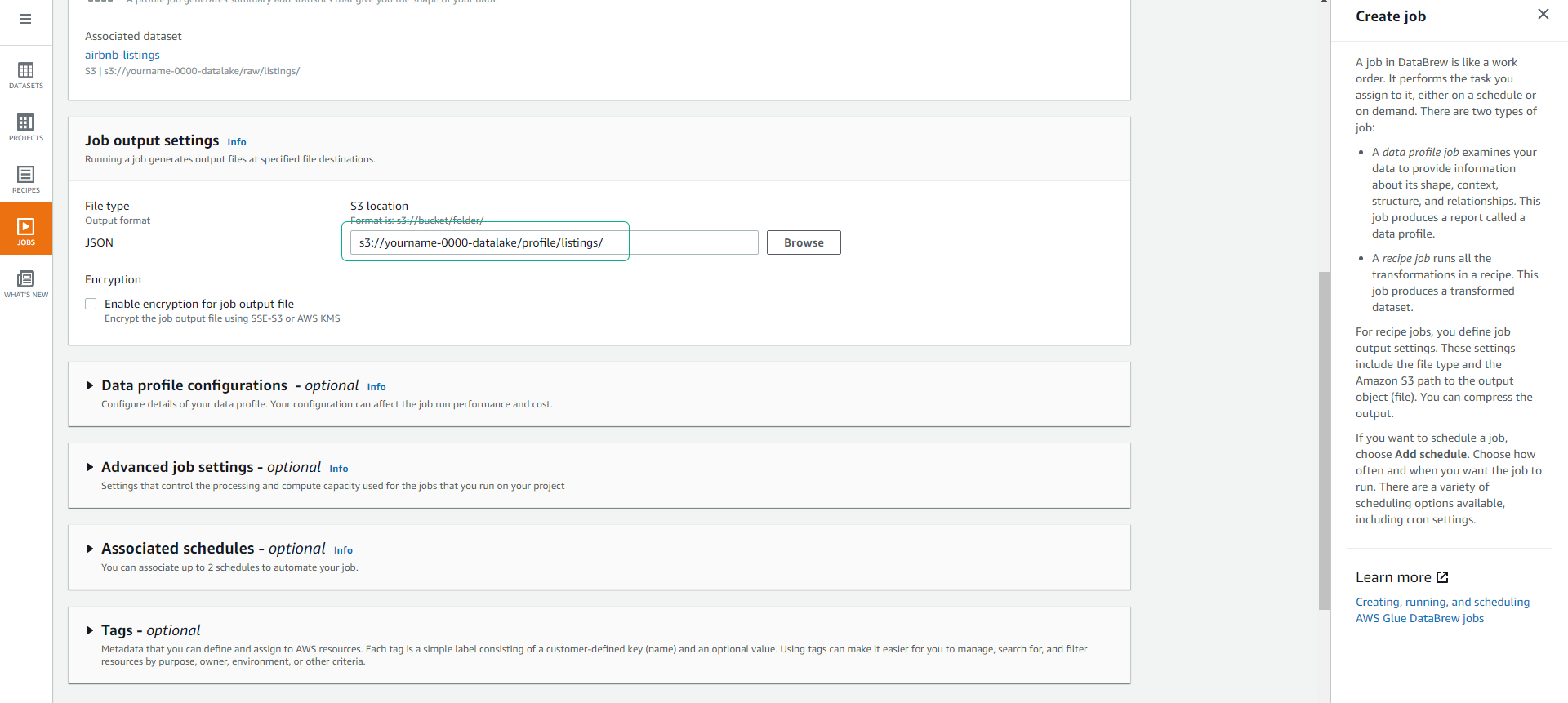
Scroll down, under Job output settings, select the S3 path s3://yourname-0000-datalake/profile/listings/.
-
Scroll down to Permissions and choose the Role AWSGlueDataBrewServiceRole-airbnb-dataset that we created earlier.
- Click Create and run job.
-
It will take a few minutes for the data profile job to complete.
View Dataset Profile
-
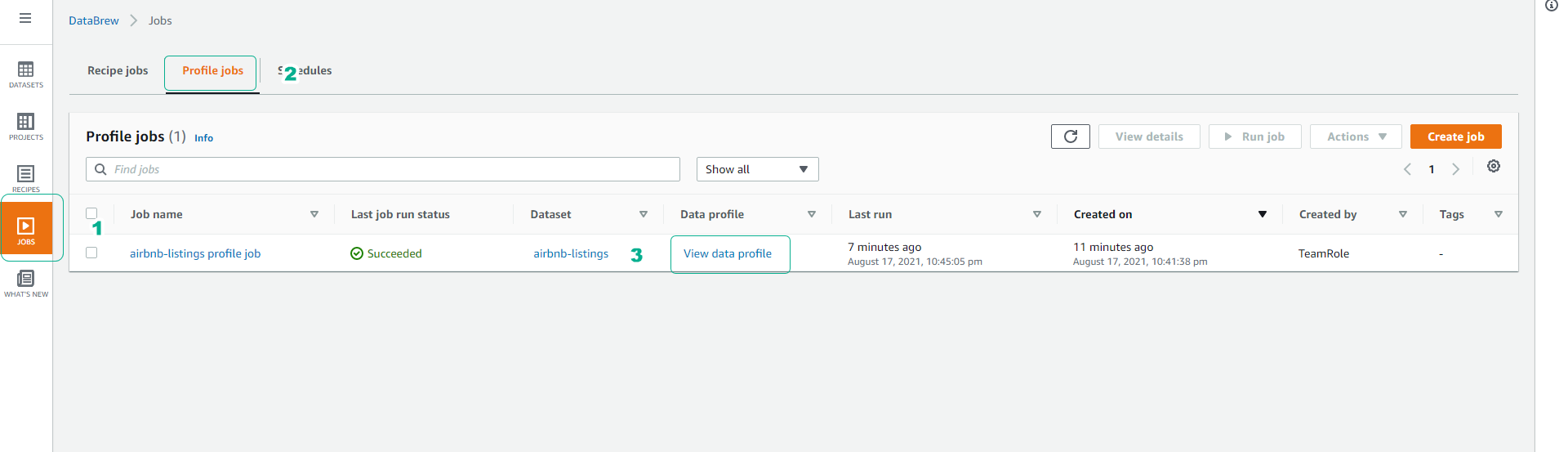
Click on the Jobs menu.
- Click on the Profile jobs tab to view data profile jobs.
- If the job is successful as shown in the image below, click View data profile.
-
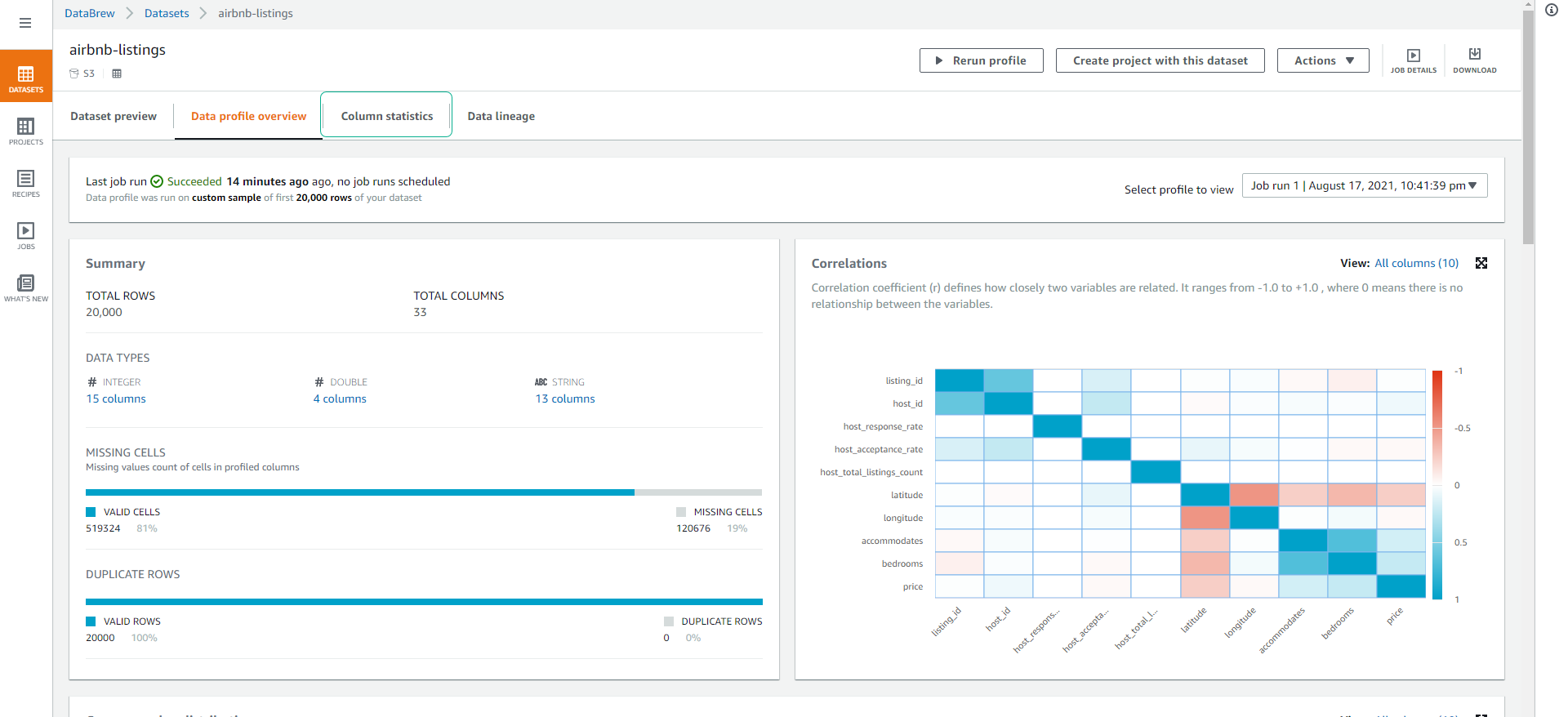
You will be able to see an overview of the number of columns, data types, missing or duplicate values, as well as the correlation between attributes in our dataset.
-
Click on the Column statistics tab where you can delve deeper into each column, check the quality of data and value distribution. This is very useful for finding columns with a low amount of duplicate data (high cardinality means little overlap), and Min, Max, and Average values.
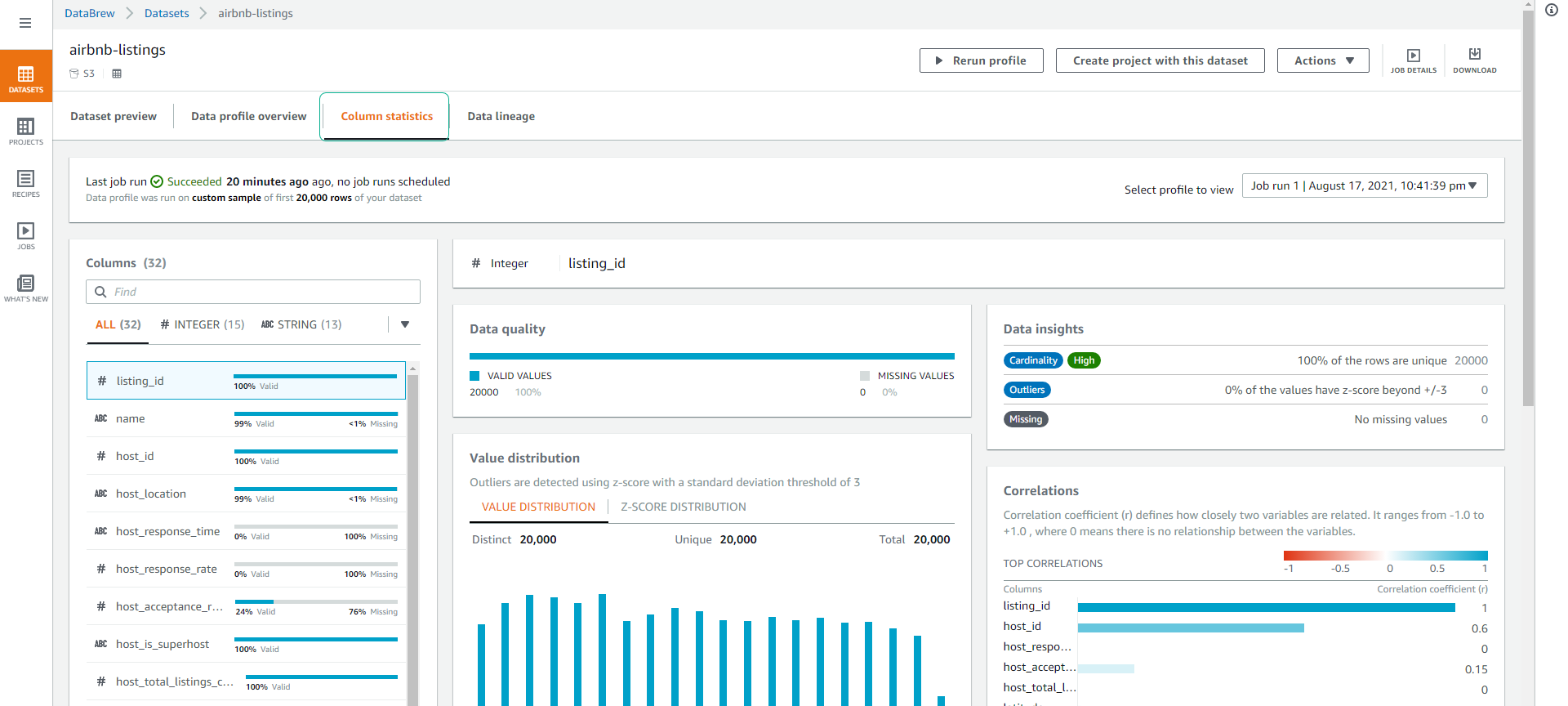
-
Click on the Data lineage tab, this view lets us see the flow of data through different stages. We can see the original data as well as jobs that have affected the dataset and where the data is stored.
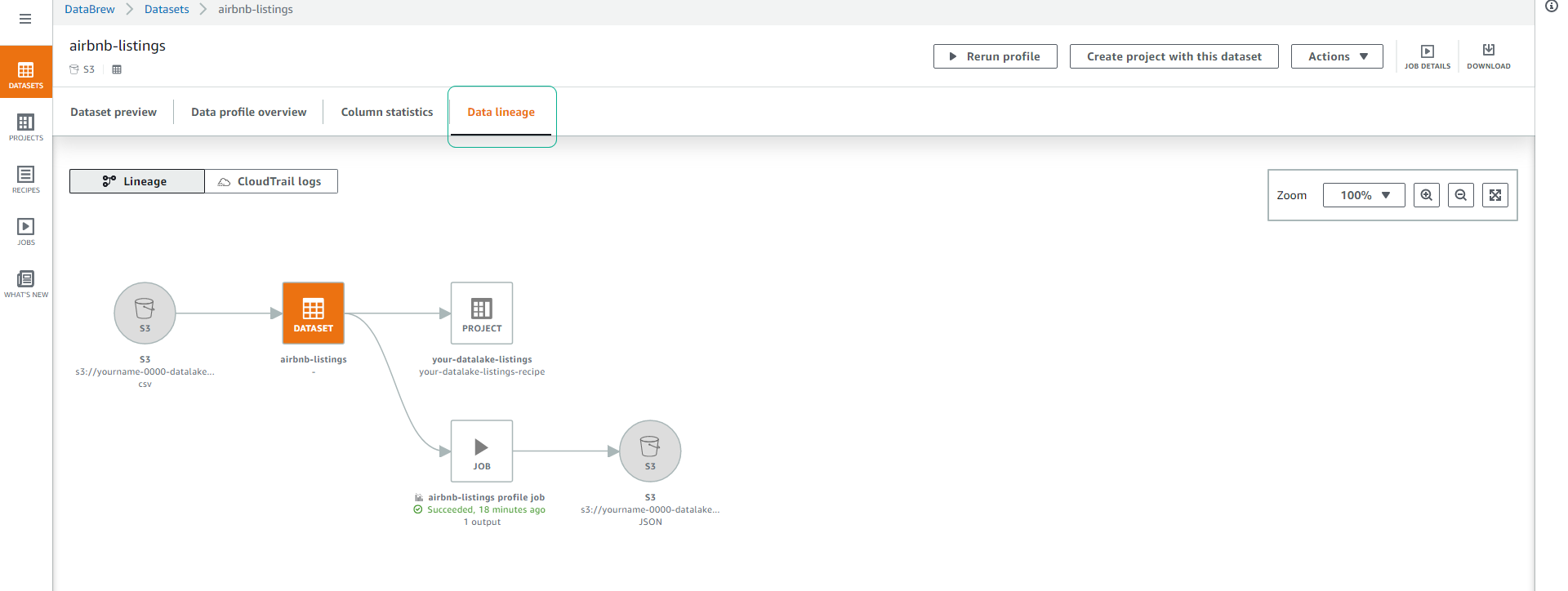
Next, we will proceed to create clean (cleaning) and transform (data transformation).