Preparing the Next Table
Preparing the Next Table
In this step, we will repeat similar steps as with the listings table for the reviews table.
Create Project
-
In the Glue DataBrew service interface, click Create project.
-
Name the project your-datalake-reviews.
- We will see the Recipe section selected by default as Create new recipe with the recipe name automatically set to the project name as your-datalake-reviews-recipe.
- Click to choose New dataset.
-
Scroll down, name the Dataset airbnb reviews.
- At the path to the S3 bucket, select the path to the reviews folder you have uploaded.
- Example: s3://yourname-0000-datalake/raw/reviews/
- Click Select the entire folder.
-
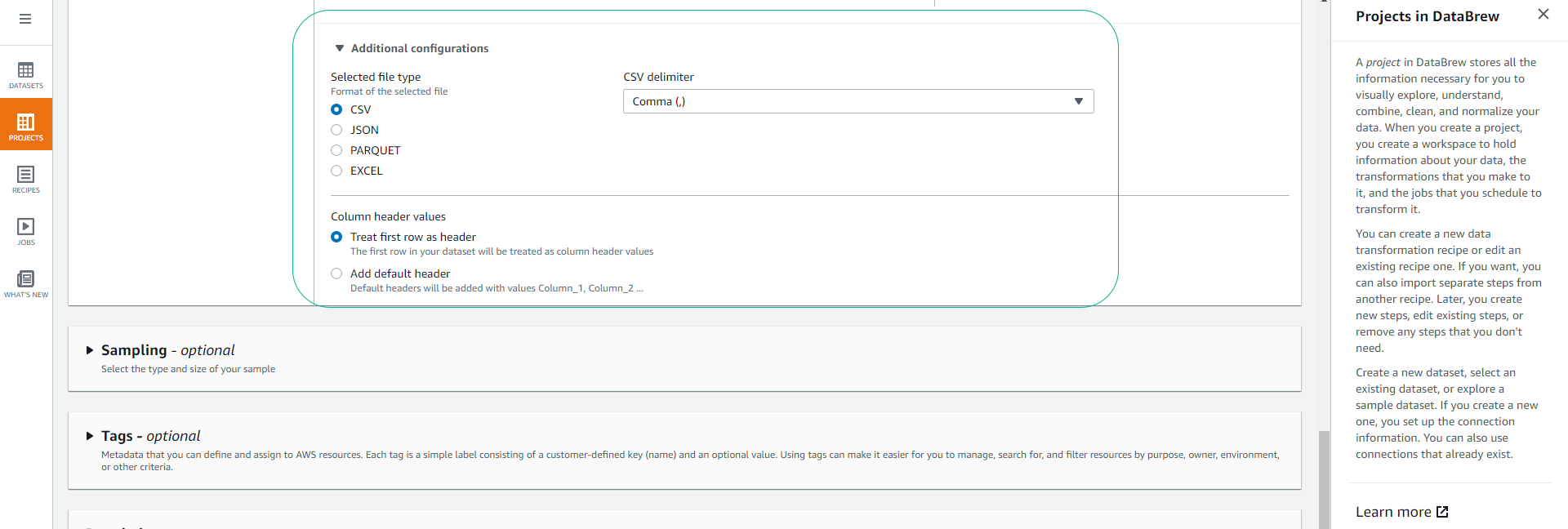
Depending on your data, we will choose the format, delimiter for data fields, and whether the data includes column names in the first row or not.
- In the case of using the Dataset attached to this workshop (airbnb listings), we will choose the default options as follows:
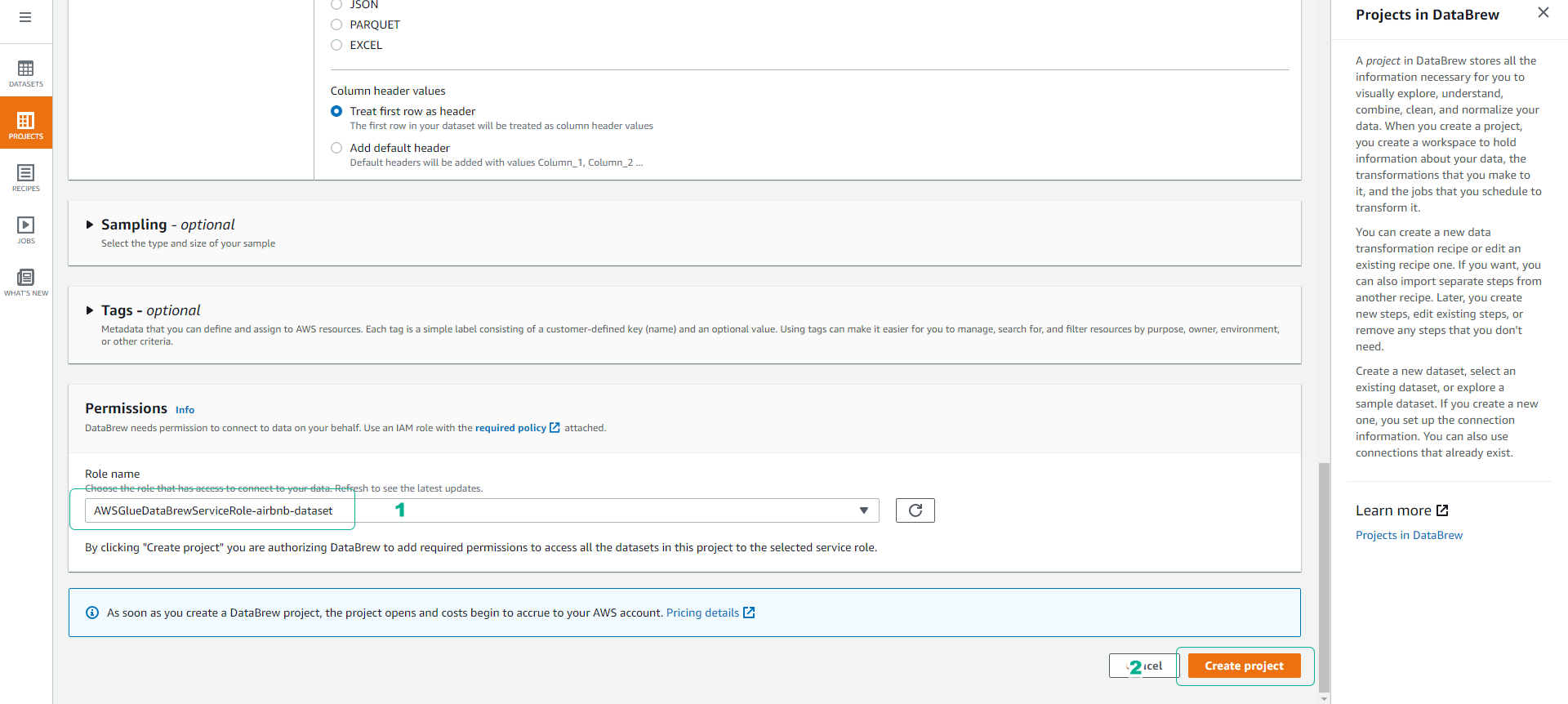
- Scroll down, at the Permissions section.
- Click to choose AWSGlueDataBrewServiceRole-airbnb-dataset.
- Click Create Project.
- Click Skip at the DataBrew feature introduction interface.
- Wait a few minutes for your session to initialize.
Transform Data
-
In the Glue DataBrew service interface, click on Projects, then click on the project name your-datalake-reviews.
-
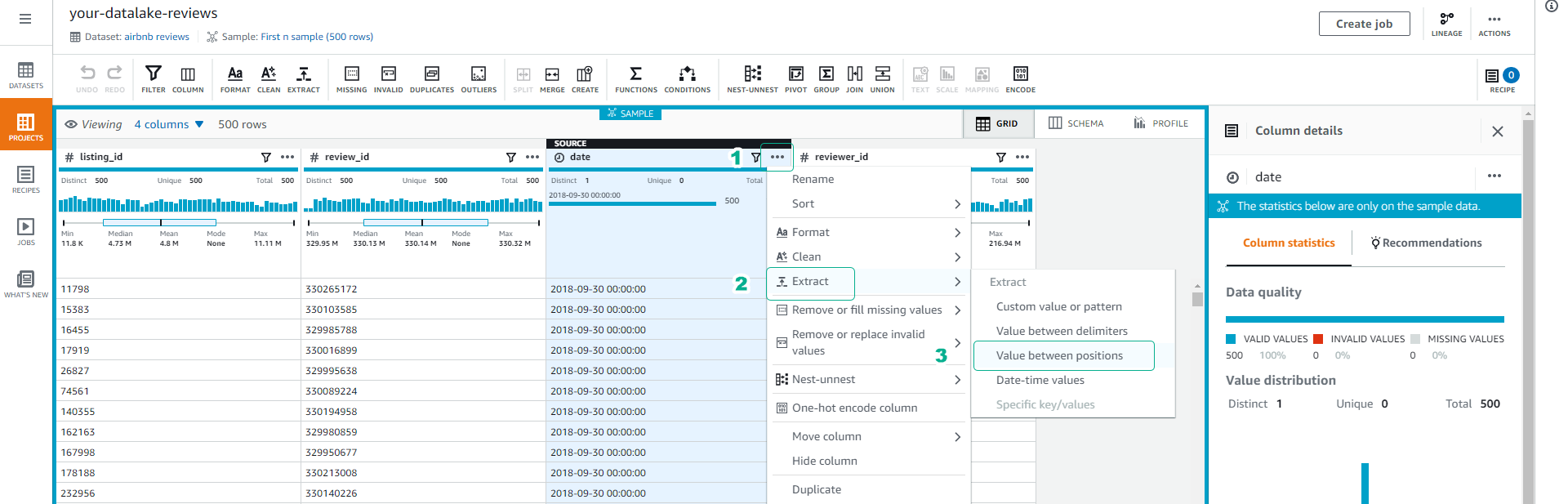
We will extract year and month information from the date column for future partitioning.
- Click the … icon of the date column.
- Click Extract.
- Click Value between position.
-
Set Starting position = 0 and Ending position = 4 to extract the first 4 characters.
- Name the extracted data column Year.
- Click Apply.
-
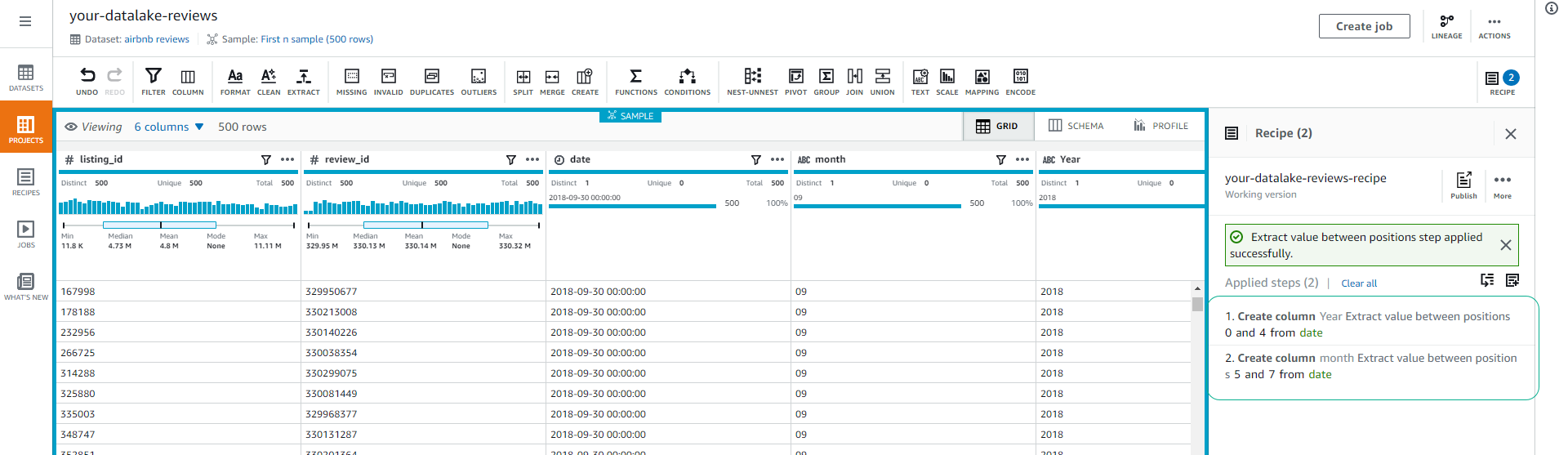
Repeat steps 2 and 3 with Starting position = 5 and Ending position = 7 to extract the month column.
-
Click Create job to create a job for cleaning and transforming data.
-
Name the job airbnb-reviews-cleantransform.
- Choose the output location for the cleaned and transformed data as S3 with the following path s3://yourname-0000-datalake/cleantransform/.
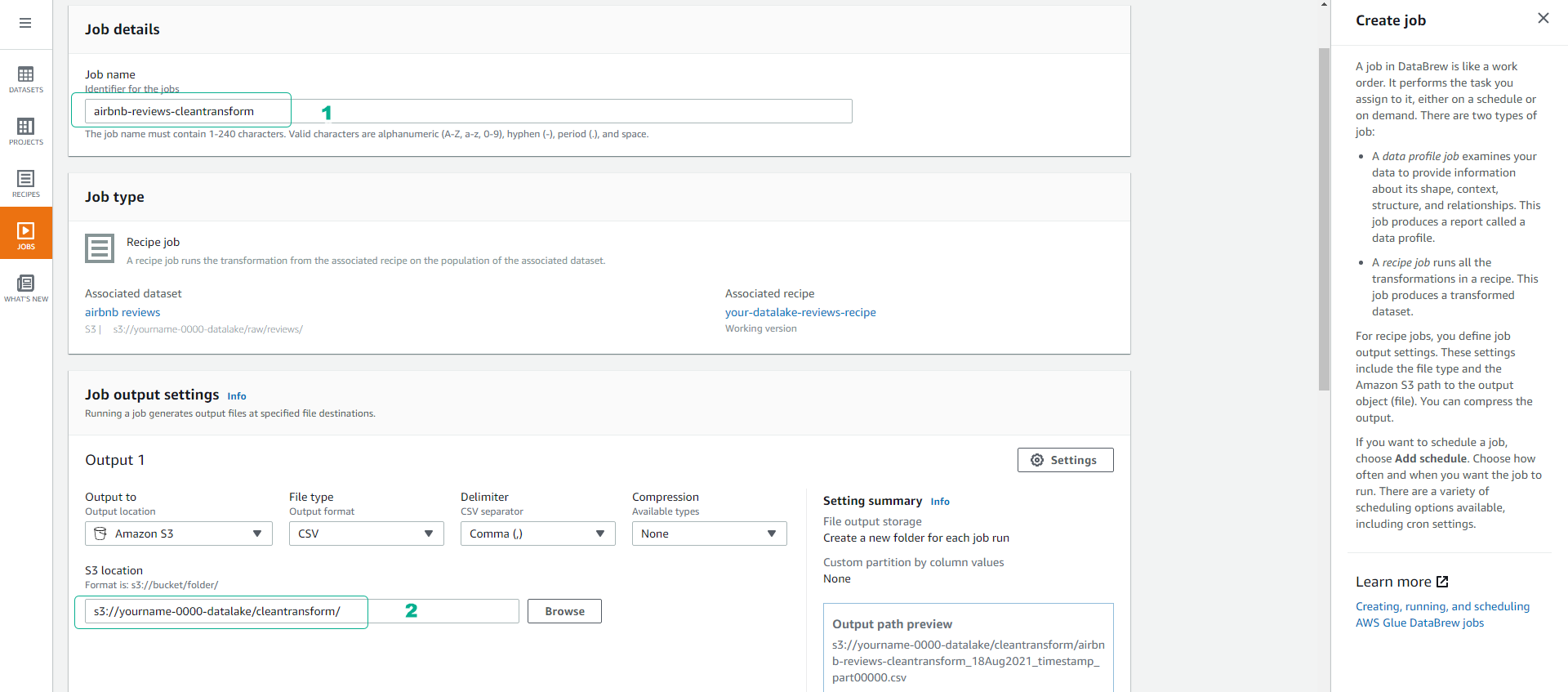
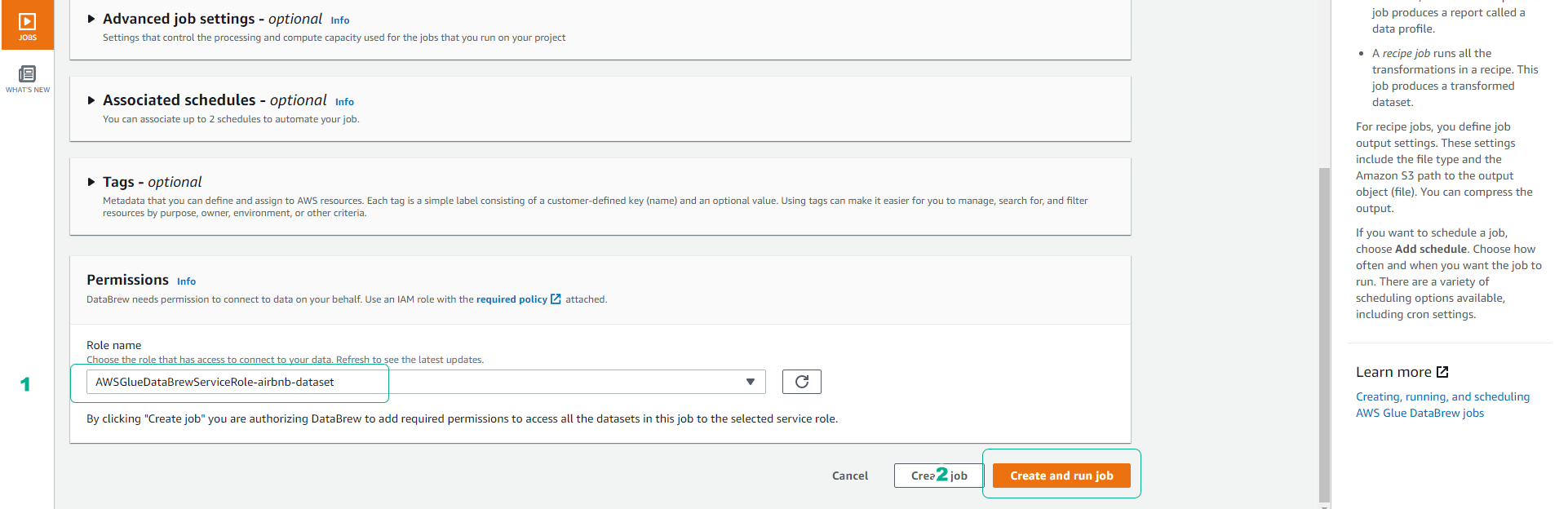
- Scroll down, click and choose the role AWSGlueDataBrewServiceRole-airbnb-dataset.
- Click Create and run job.
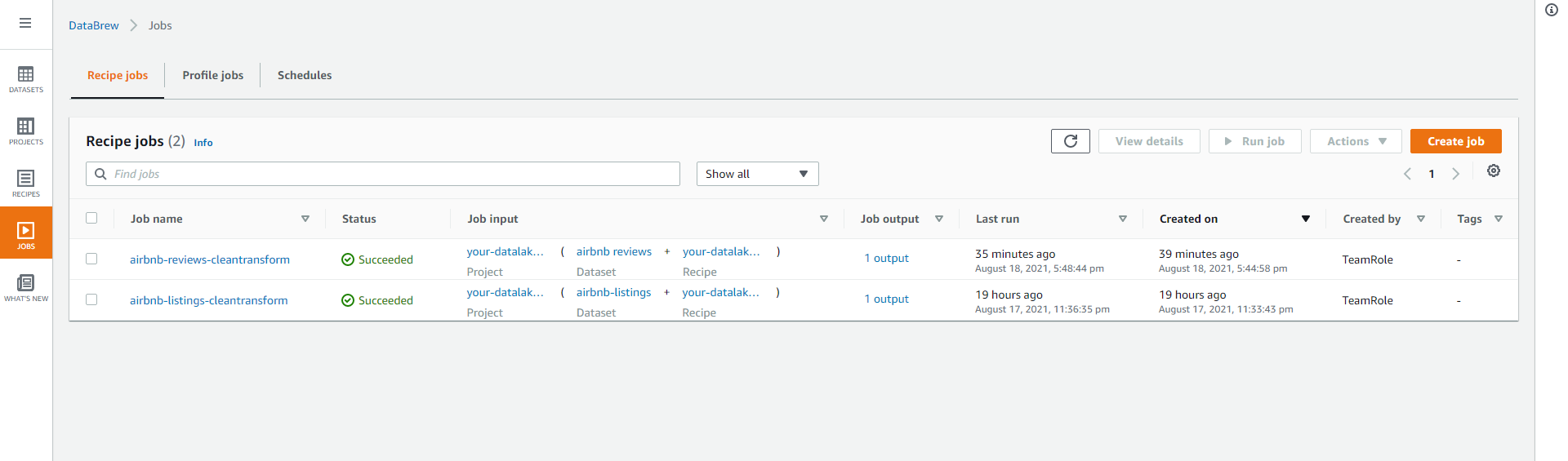
- You can check the job status in the Job section.
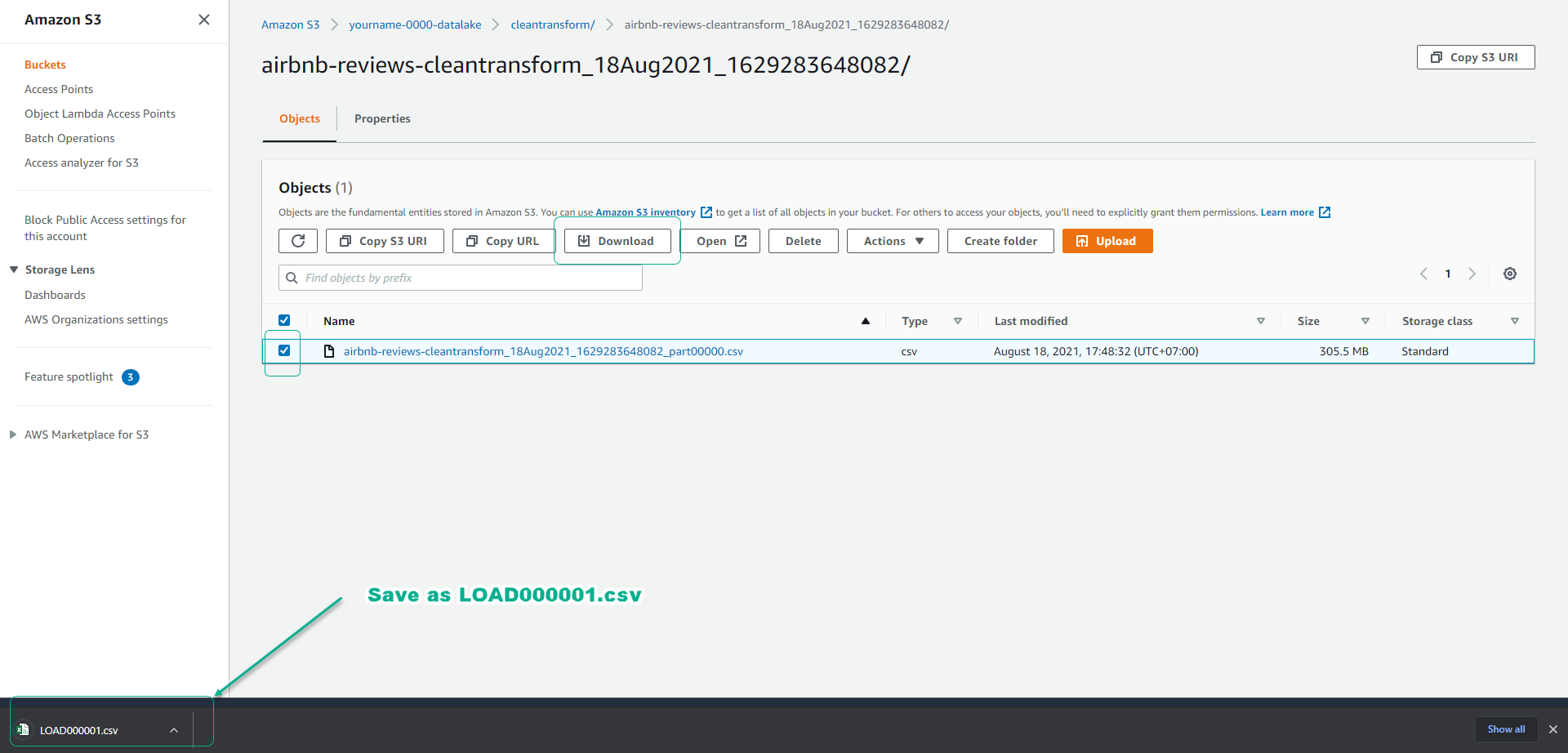
- After the job is completed, access the S3 bucket yourname-0000-datalake/cleantransform/ to view the cleaned and transformed data.
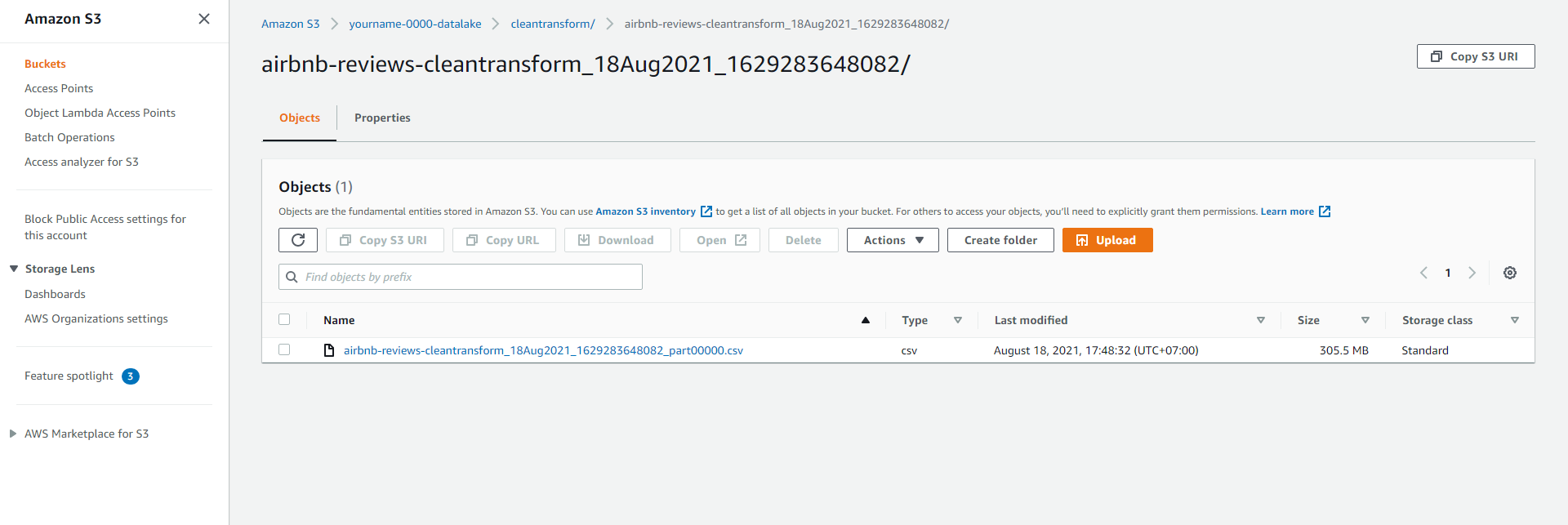
- Click to select the cleaned and transformed csv data.
- Click Download.
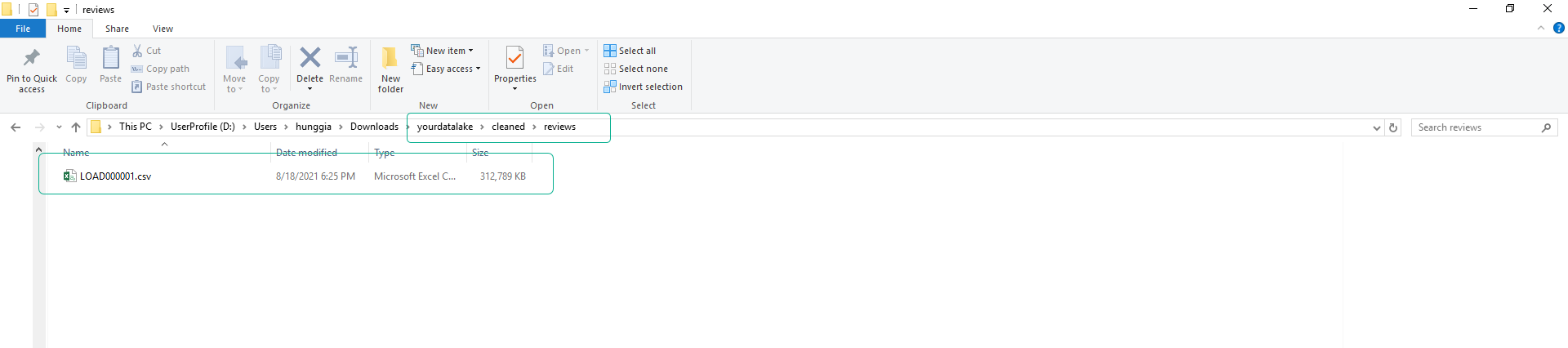
- Name the file LOAD000001.csv.
- Set the folder structure similar to our original dataset.
We will perform cleaning and transformation of the data for the reviews table, then we will proceed to upload the cleaned data to the S3 bucket.