Transform to Parquet-2
Convert to Parquet - reviews table
- Go to AWS Glue service
- Click Jobs.
- Click Add job.
- At Configure the job properties page.
- Name the Job name as yourname-datalake-csvtoparquet-reviews.
- Select the IAM role as AWSGlueServiceRole-yourname-datalake.
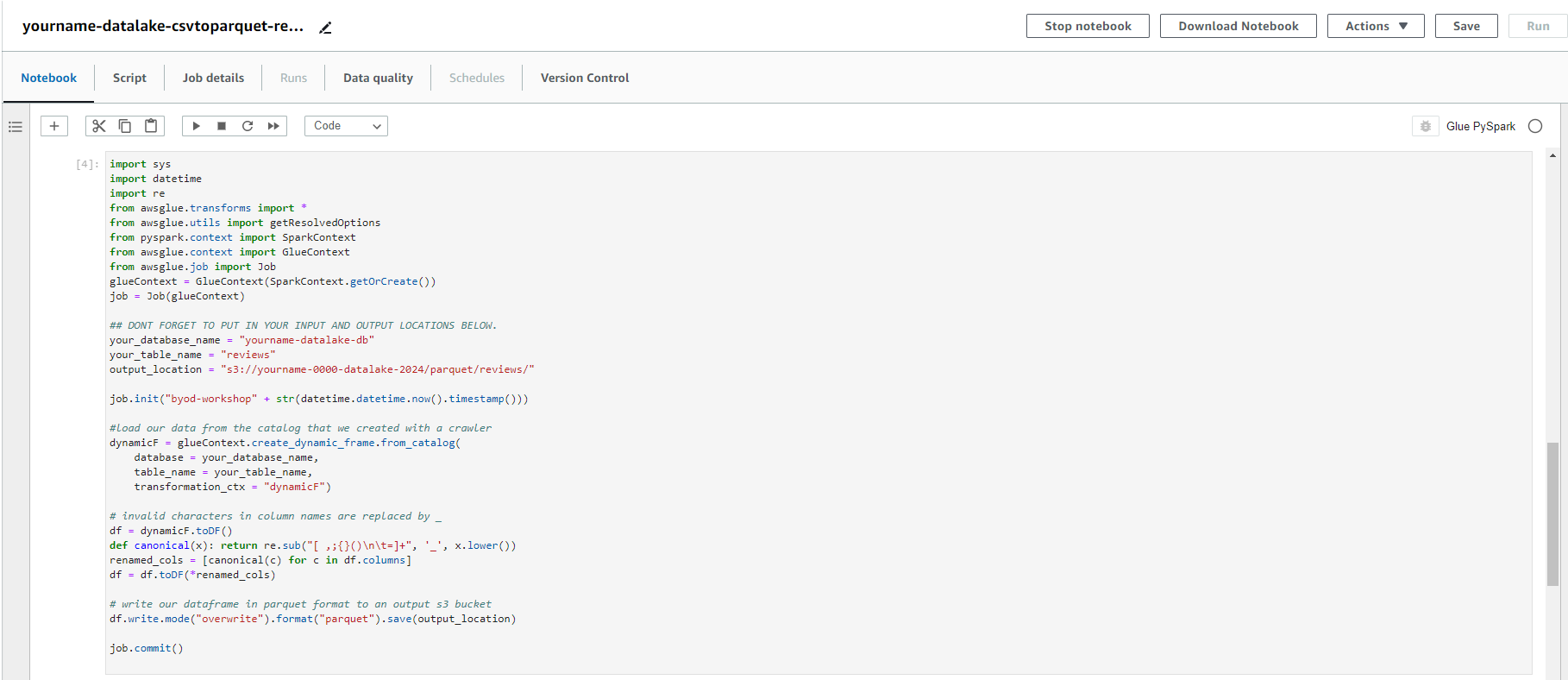
- Copy the python script below into the edit script screen.
- Note to rename s3 bucket and glue database to match your configuration.
import sys
import datetime
import re
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
glueContext = GlueContext(SparkContext.getOrCreate())
job = Job(glueContext)
## DONT FORGET TO PUT IN YOUR INPUT AND OUTPUT LOCATIONS BELOW.
your_database_name = "yourname-datalake-db"
your_table_name = "reviews"
output_location = "s3://yourname-0000-datalake/parquet/reviews/"
job.init("byod-workshop" + str(datetime.datetime.now().timestamp()))
#load our data from the catalog that we created with a crawler
dynamicF = glueContext.create_dynamic_frame.from_catalog(
database = your_database_name,
table_name = your_table_name,
transformation_ctx = "dynamicF")
# invalid characters in column names are replaced by _
df = dynamicF.toDF()
def canonical(x): return re.sub("[ ,;{}()\n\t=]+", '_', x.lower())
renamed_cols = [canonical(c) for c in df.columns]
df = df.toDF(*renamed_cols)
# write our dataframe in parquet format to an output s3 bucket
df.write.mode("overwrite").format("parquet").save(output_location)
job.commit()
- Click Save.
- Click Run job, click Run job to confirm.
- Access AWS Glue service
- Click Jobs.
- Click to select yourname-datalake-csvtoparquet-reviews job.
- Monitor the job until the job runs successfully.
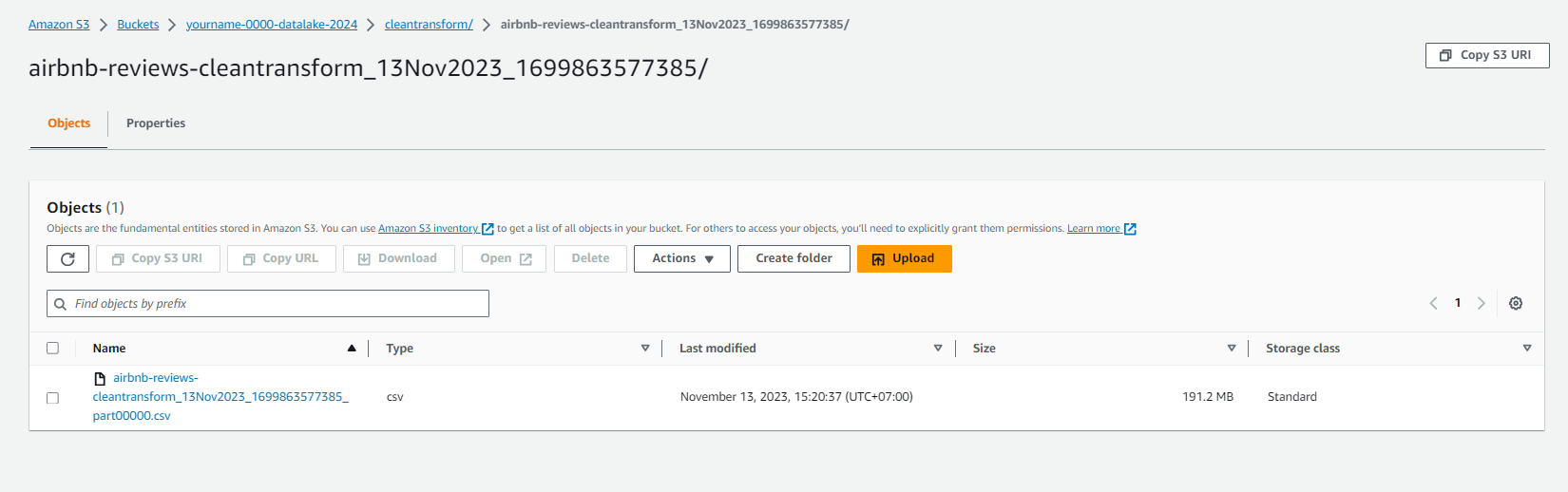
- Check the data in S3 bucket yourname-0000-datalake/parquet/reviews/.
- You will see that the data has been converted to parquet format and compressed very well.
In this step we have created a job to convert our data from CSV to Parquet format for the data of the reviews table. Next we will create a job crawler to discover and store the metadata of the dataset in the form of the parquet we just converted, then save it to the Glue data catalog.