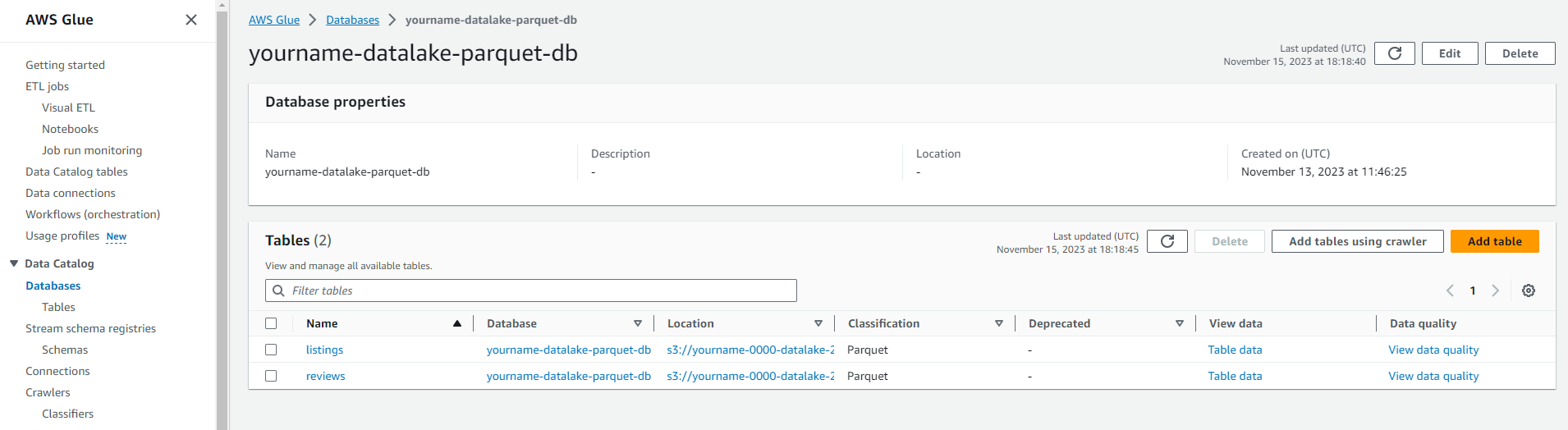
Creating a New Data Catalog
Creating a Data Catalog
-
Access the AWS Glue service
- Click Crawlers.
- Click Add crawler.
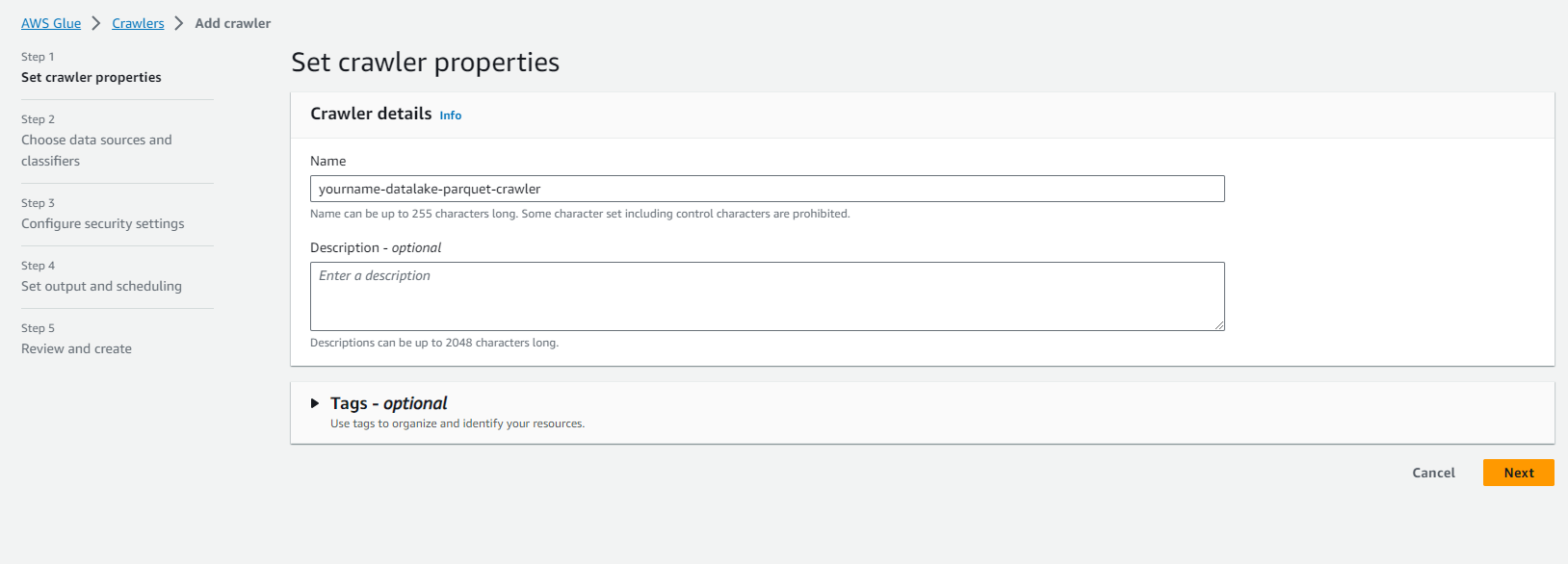
-
On the Add information about your crawler page.
- Set the Crawler name to yourname-datalake-parquet-crawler.
- Click Next.
-
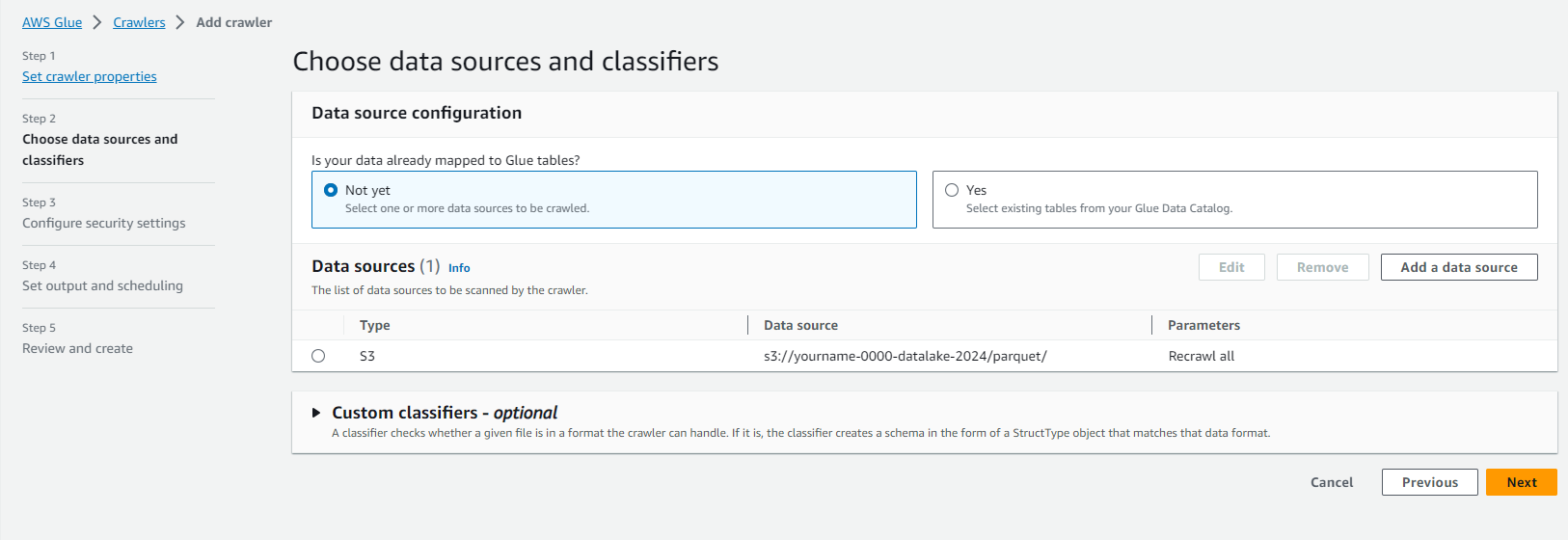
On the Specify crawler source type page.
- Keep the default options.
- Crawler source type: Data stores.
- Repeat crawls of S3 data stores: Crawl all folders.
- Click Next.
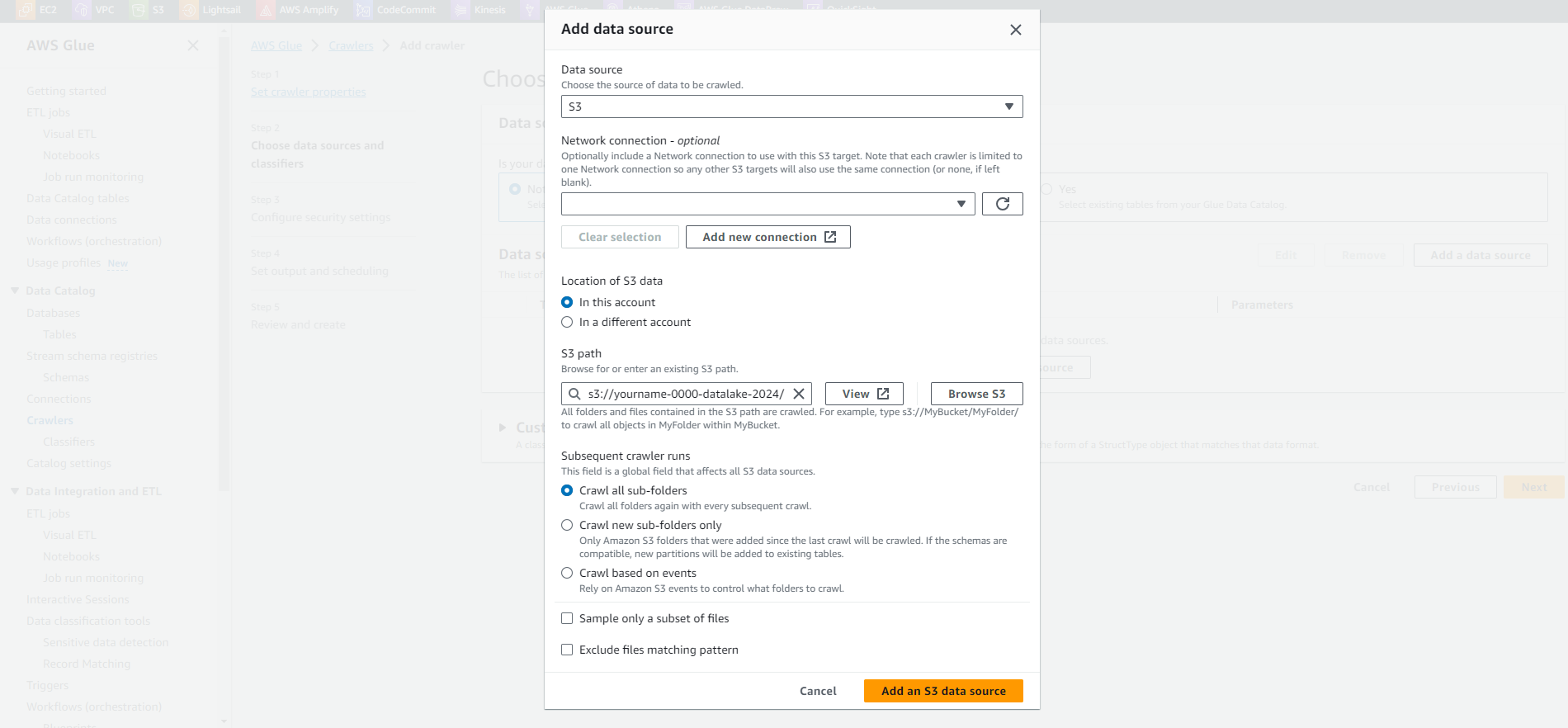
- Keep the default options.
-
On the Add a data store page.
- Keep the S3 option at Choose a data store.
- In the Include path field, enter the path to the cleaned dataset uploaded to S3.
- Example: s3://yourname-0000-datalake/parquet/
- Click Next.
-
On the Add another data store page.
- Keep the No option.
- Click Next.
-
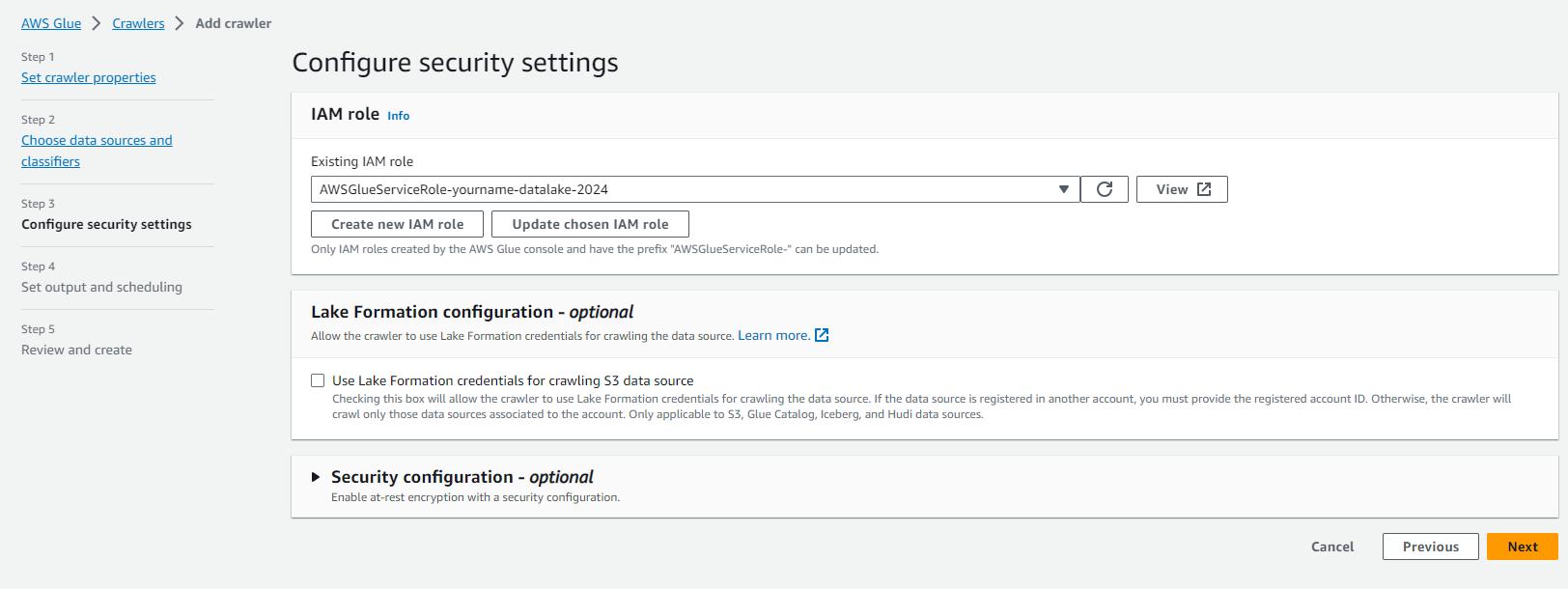
On the Choose an IAM role page.
- Click Choose an existing IAM role.
- In the IAM Role section, select the role AWSGlueServiceRole-yourname-datalake.
- Click Next.
-
On the Create a schedule for this crawler page.
- Keep the Run on demand option.
- Click Next.
-
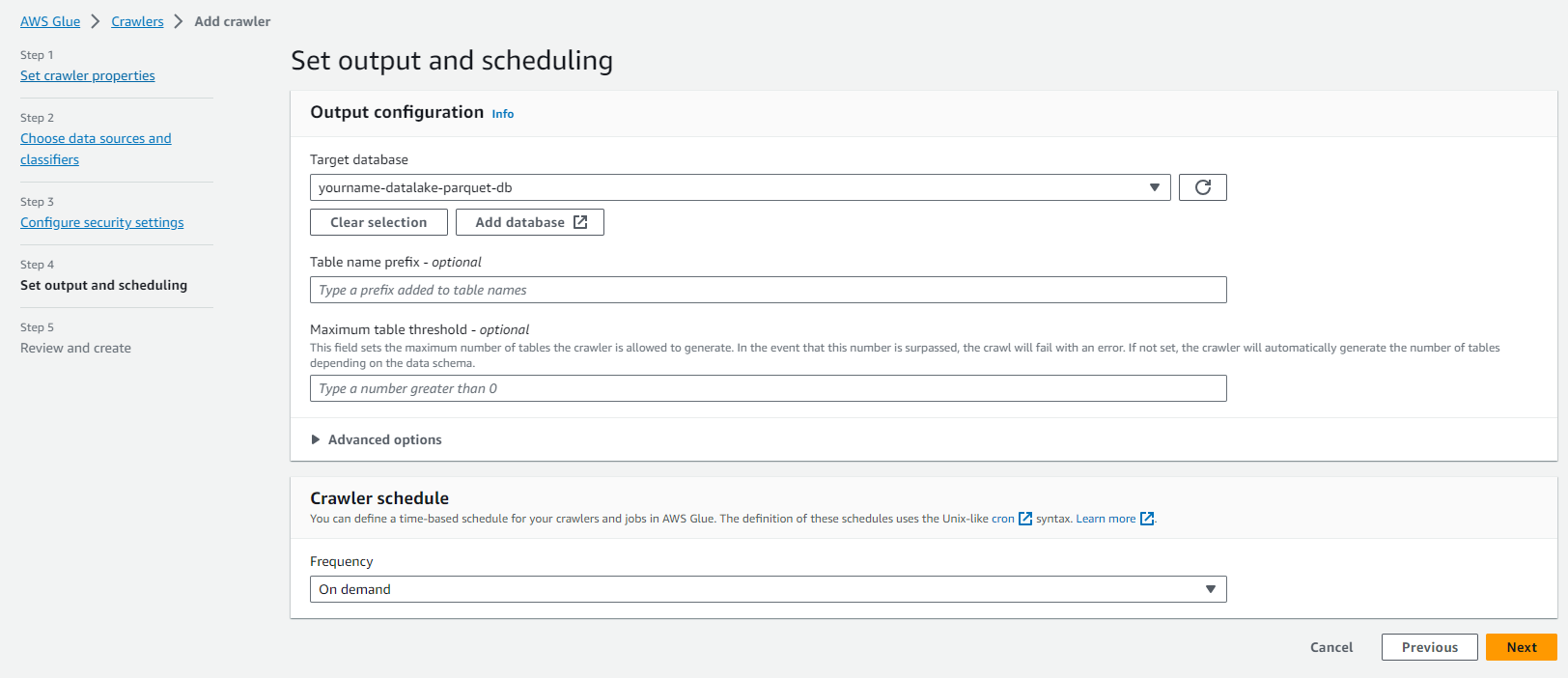
On the Configure the crawler’s output page.
- Click Add database.
- Enter the Database name as yourname-datalake-parquet-db.
- Click Next.
- Click Finish to proceed with creating the Crawler.
-
Click on yourname-datalake-crawler.
- Click Run crawler.
- Check that the Crawler runs successfully as shown in the image below.
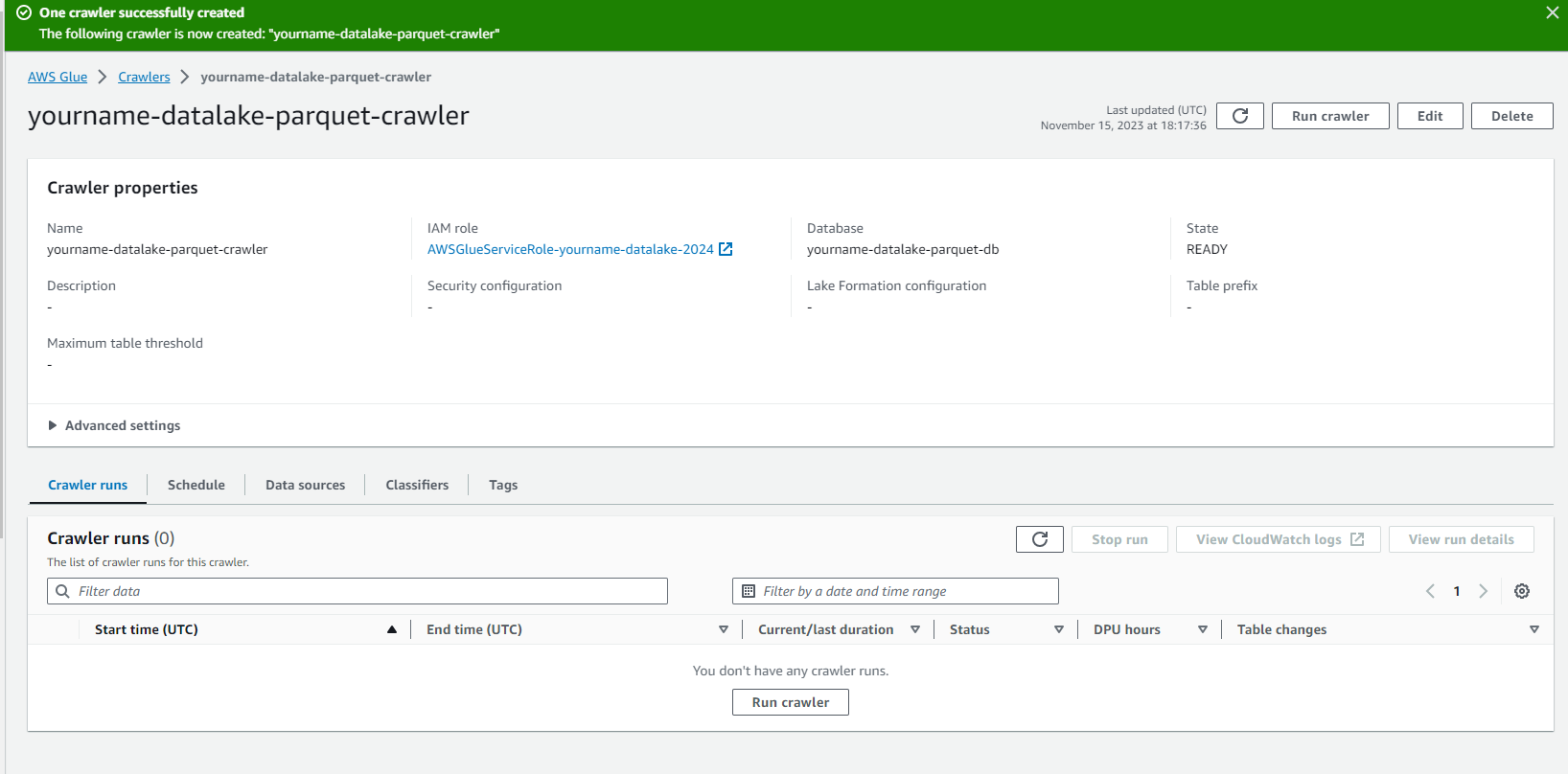
At this stage, we have created a Crawler job to explore data and save metadata information into the Glue data catalog for data converted to parquet.