Partition dữ liệu
Partition dữ liệu trong Athena
Trong bước này chúng ta sẽ thực hiện truy vấn dữ liệu với các câu truy vấn cơ bản.
- Thực hiện câu query dưới đây để tạo một bảng mới có dữ liệu được partition theo year.
create table reviews_partition
WITH (
format = 'PARQUET',
external_location = 's3://yourname-0000-datalake/parquet/reviews_partition',
partitioned_by = ARRAY['year']
)
AS SELECT reviews.listing_id,reviews.review_id,reviews.date,reviews.reviewer_id,reviews.year as year
FROM reviews;
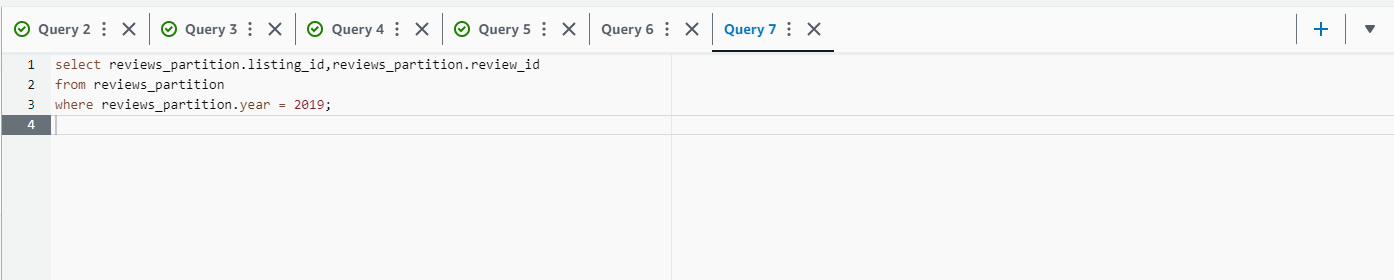
- Thực hiện câu truy vấn dưới đây.
select reviews_partition.listing_id,reviews_partition.review_id
from reviews_partition
where reviews_partition.year = 2019;
Chúng ta có thể thấy, lượng dữ liệu scan được giảm đi rất nhiều khi sử dụng partition. Điều đó sẽ giúp chúng ta tối ưu hiệu năng và chi phí. Chúng ta có thể lựa chọn bất kì cột nào để thực hiện partition dữ liệu, tuy nhiên thông thường chúng ta thường partition dữ liệu theo thời gian.
- Thực hiện câu truy vấn dưới đây và so sánh lượng dữ liệu scan khi truy vấn vào table không được partition.
select reviews.listing_id,reviews.review_id
from reviews
where reviews.year = 2019;
Lượng dữ liệu cần scan của table không được partition cao gấp ~ 3 lần.
