Tranform sang Parquet
Tranform sang Parquet - listings table
- Truy cập vào dịch vụ AWS Glue
- Click ETL Jobs.
- Click Notebooks.
- Click Notebook
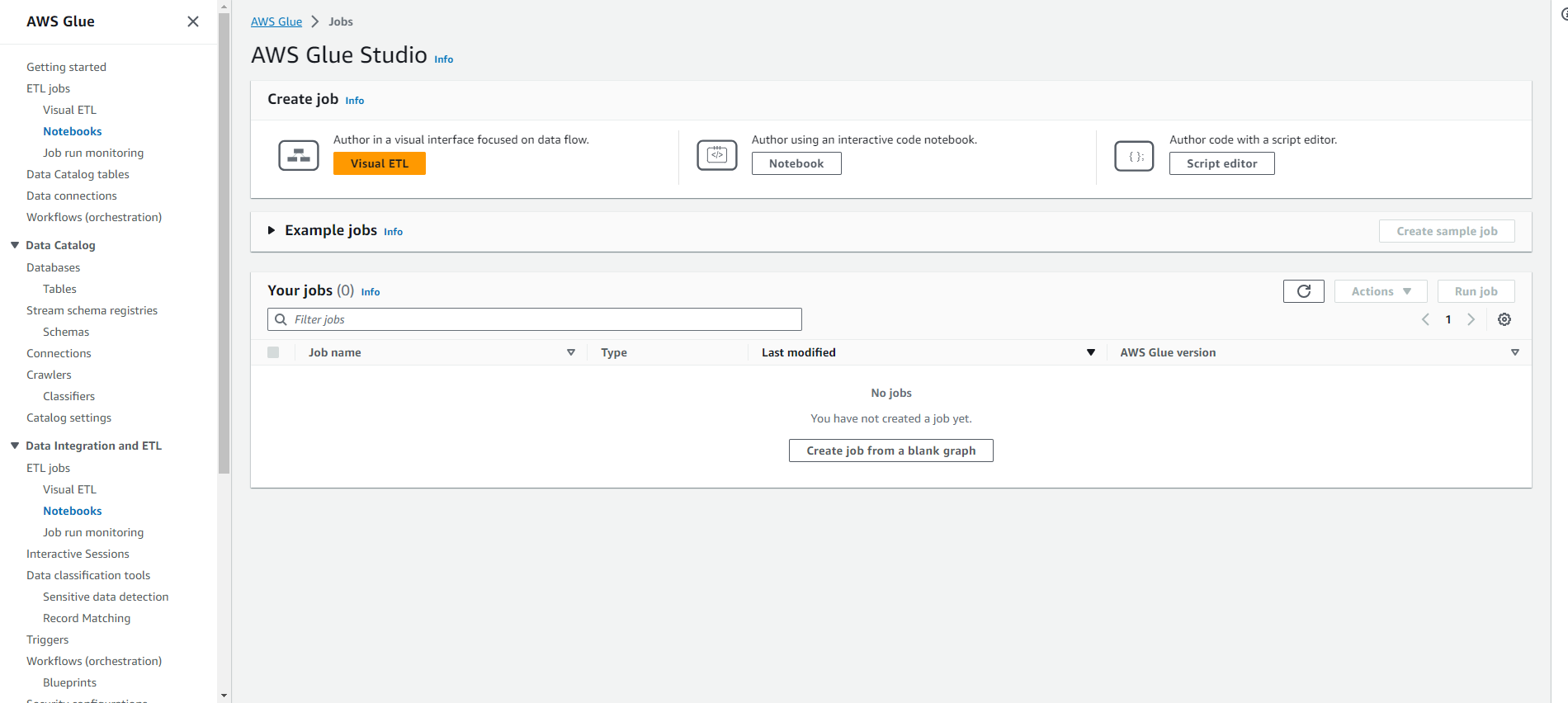
- Tại trang Configure the job properties.
- Đặt tên Job name là yourname-datalake-csvtoparquet.
- Chọn IAM role là AWSGlueServiceRole-yourname-datalake.
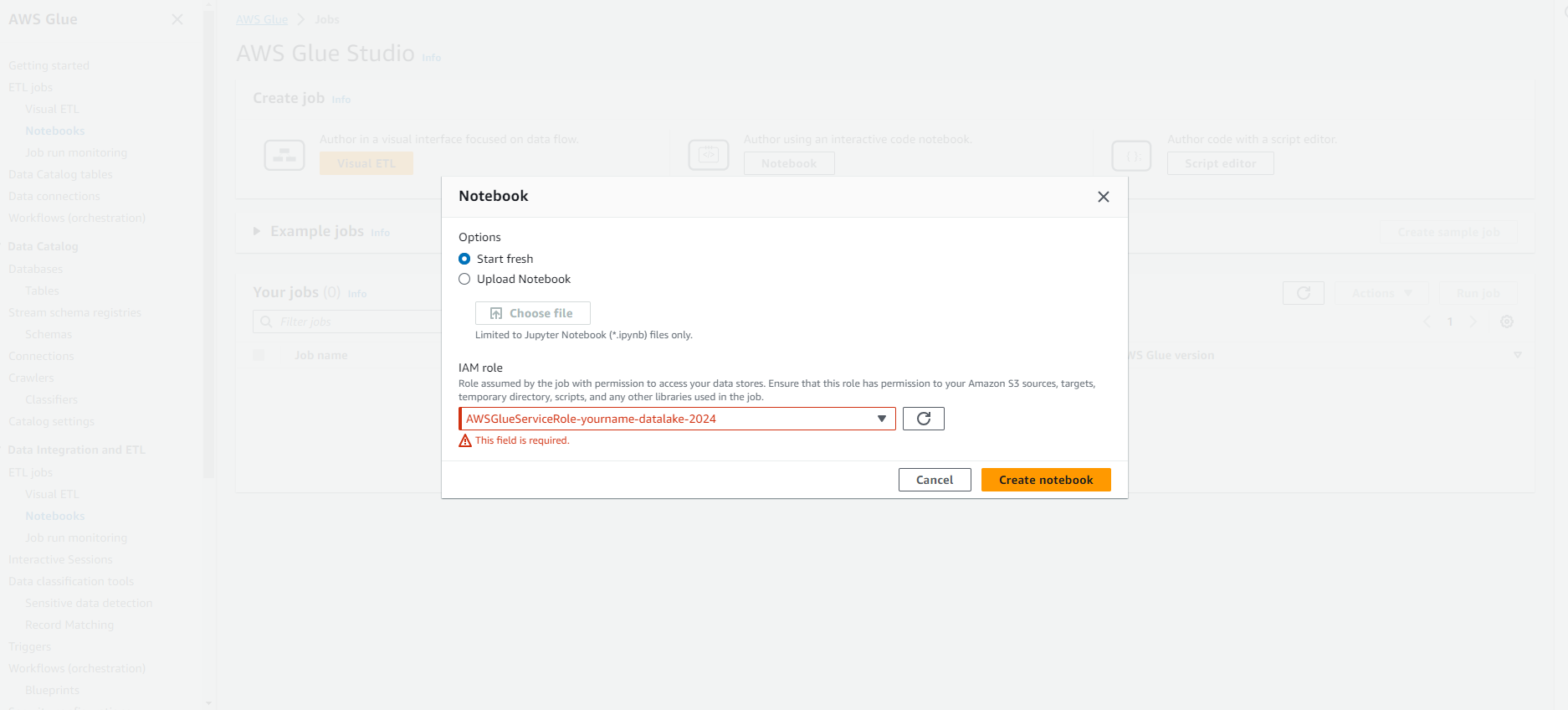
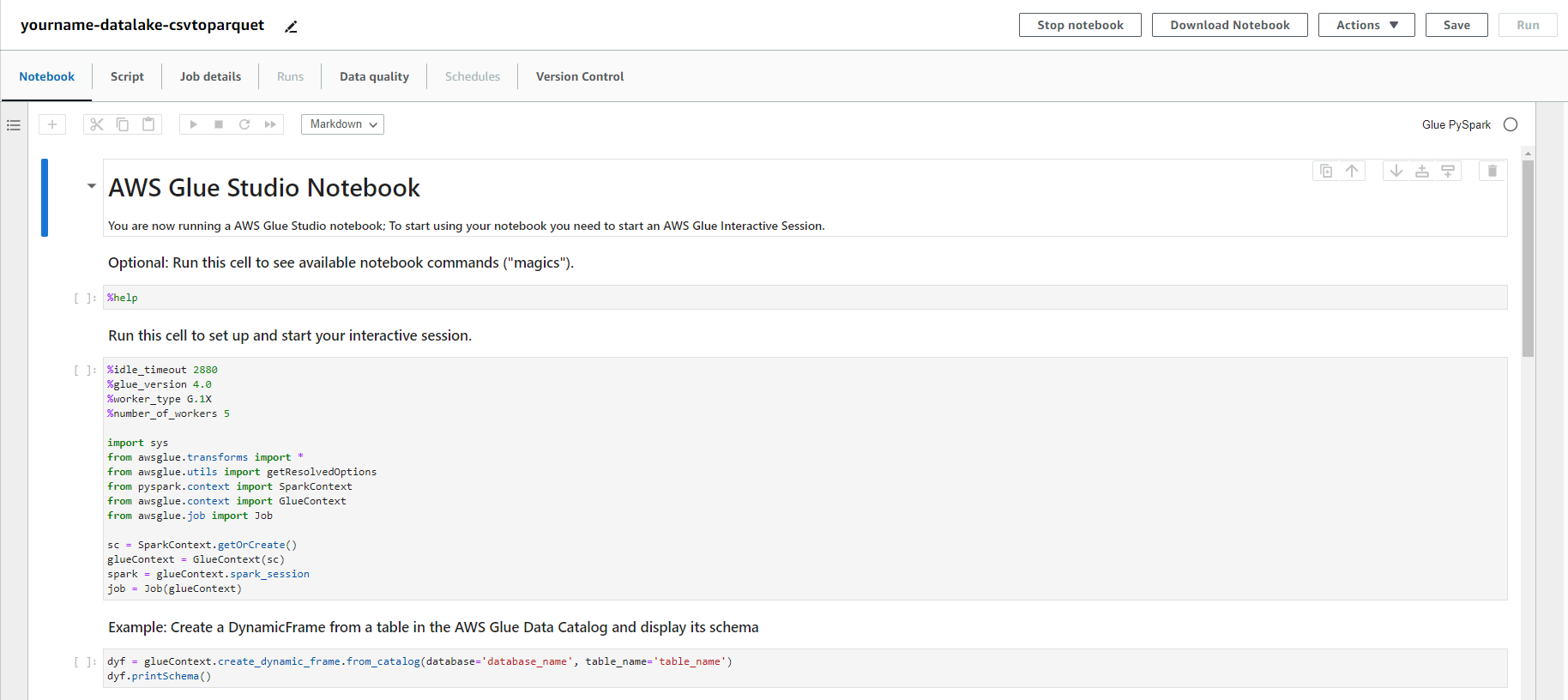
- Copy đoạn script python dưới đây vào màn hình edit script.
- Lưu ý đổi tên s3 bucket , glue database đúng với cấu hình của bạn.
import sys
import datetime
import re
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
glueContext = GlueContext(SparkContext.getOrCreate())
job = Job(glueContext)
## DONT FORGET TO PUT IN YOUR INPUT AND OUTPUT LOCATIONS BELOW.
your_database_name = "yourname-datalake-db"
your_table_name = "listings"
output_location = "s3://yourname-0000-datalake/parquet/listings/"
job.init("byod-workshop" + str(datetime.datetime.now().timestamp()))
#load our data from the catalog that we created with a crawler
dynamicF = glueContext.create_dynamic_frame.from_catalog(
database = your_database_name,
table_name = your_table_name,
transformation_ctx = "dynamicF")
# invalid characters in column names are replaced by _
df = dynamicF.toDF()
def canonical(x): return re.sub("[ ,;{}()\n\t=]+", '_', x.lower())
renamed_cols = [canonical(c) for c in df.columns]
df = df.toDF(*renamed_cols)
# write our dataframe in parquet format to an output s3 bucket
df.write.mode("overwrite").format("parquet").save(output_location)
job.commit()
- Click Save.
- Click Run job, click Run job để xác nhận.
- Truy cập vào dịch vụ AWS Glue
- Click Jobs.
- Click chọn yourname-datalake-csvtoparquet job.
- Theo dõi job cho đến khi job chạy thành công.
- Kiểm tra dữ liệu trong S3 bucket yourname-0000-datalake/parquet/listings/.
- Bạn sẽ thấy dữ liệu đã được chuyển sang dạng parquet và được nén lại rất tốt.
Ở bước này chúng ta đã tạo job để chuyển dữ liệu của chúng ta từ dạng CSV sang dạng Parquet cho dữ liệu của table listings. Tiếp theo chúng ta sẽ làm tương tự cho table reviews