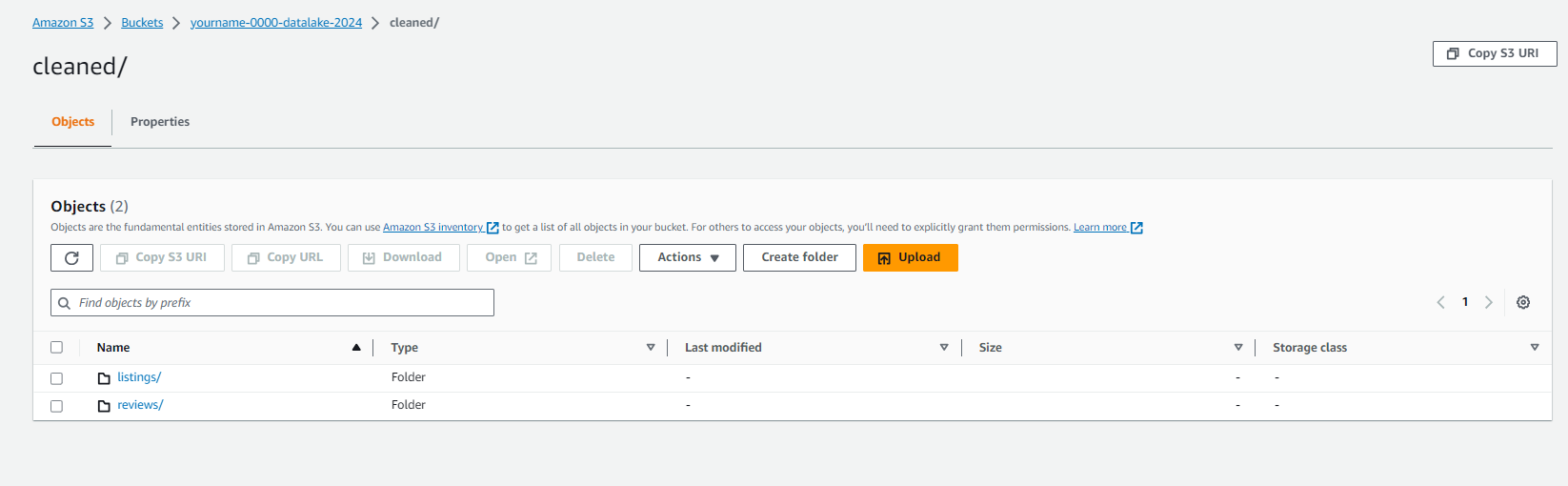
Tạo Data catalog
Tạo Data catalog
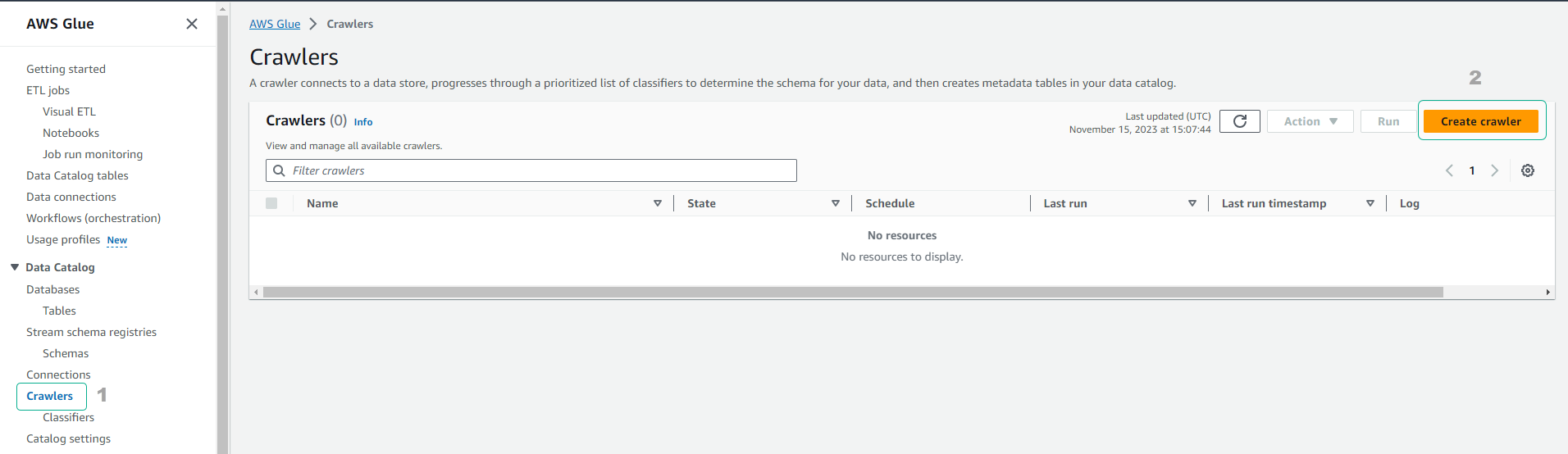
- Truy cập vào dịch vụ AWS Glue
- Click Crawlers.
- Click Add crawler.
- Tại trang Add information about your crawler.
- Đặt tên Crawler name là yourname-datalake-crawler.
- Click Next.
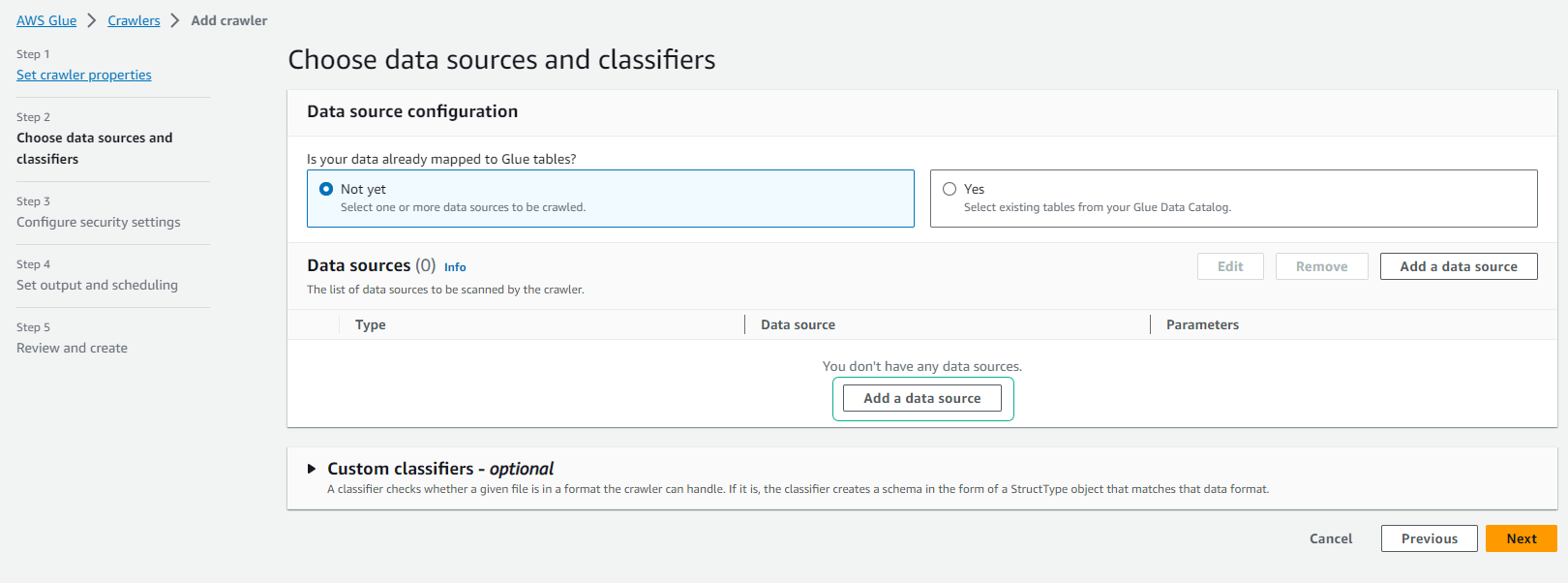
- Tại trang Specify crawler source type
- Giữ nguyên tùy chọn mặc định.
- Click Next.
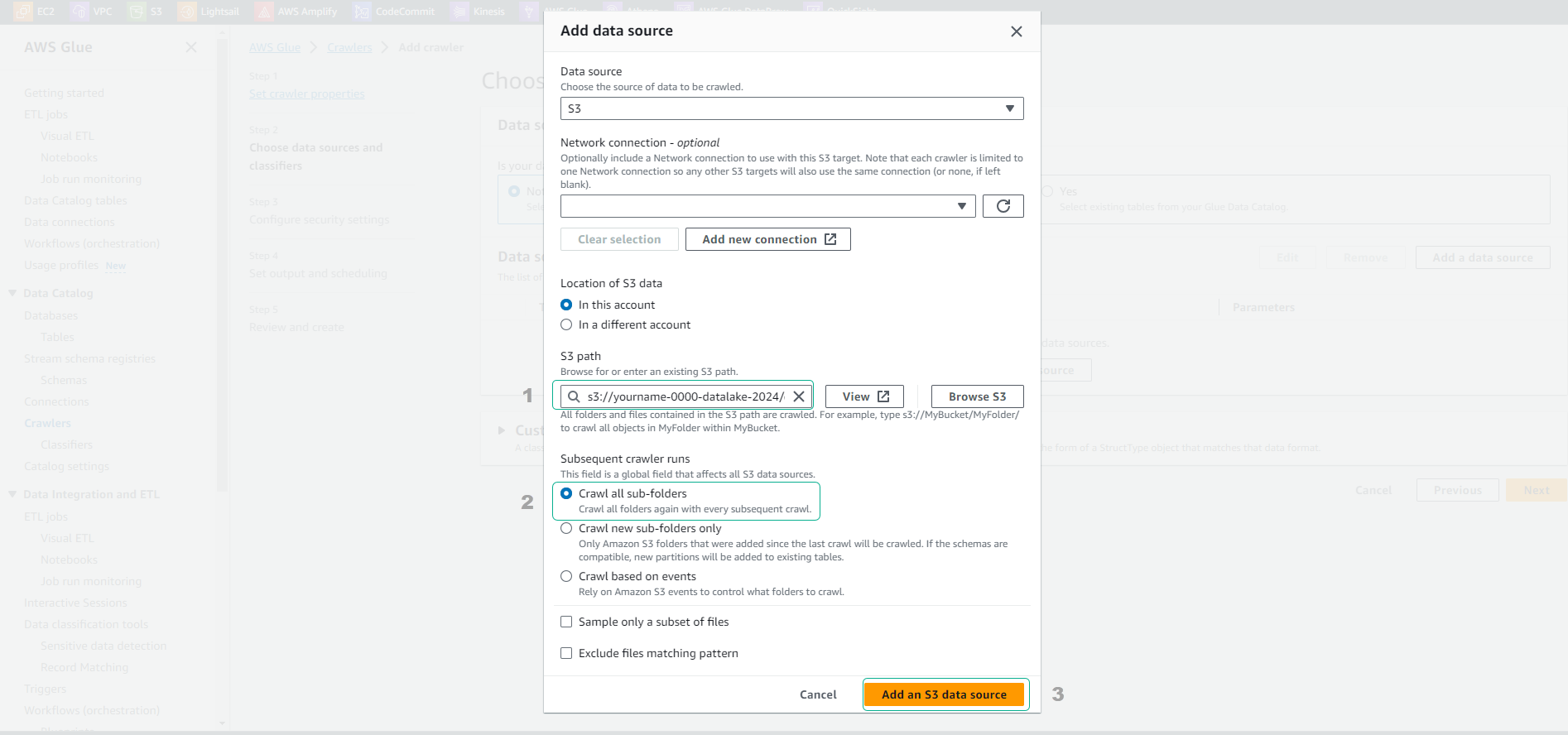
- Tại trang Add a data store.
- Giữ nguyên tùy chọn S3 tại Choose a data store.
- Tại mục Include path điền đường dẫn tới dataset cleaned chúng ta đã upload lên S3.
- Ví dụ: s3://yourname-0000-datalake/cleaned/
- Click Next.
- Tại trang Add another data store.
- Giữ nguyên lựa chọn No.
- Click Next.
- Tại trang Choose an IAM role.
- Click chọn Choose an existing IAM role.
- Tại mục IAM Role, chọn role AWSGlueServiceRole-yourname-datalake.
- Click Next.
- Tại trang Create a schedule for this crawler.
- Giữ nguyên tùy chọn Run on demand.
- Click Next.
- Tại trang Configure the crawler’s output
- Click Add database.
- Điền Database name là yourname-datalake-db.
- Click Create.
- Click Next.
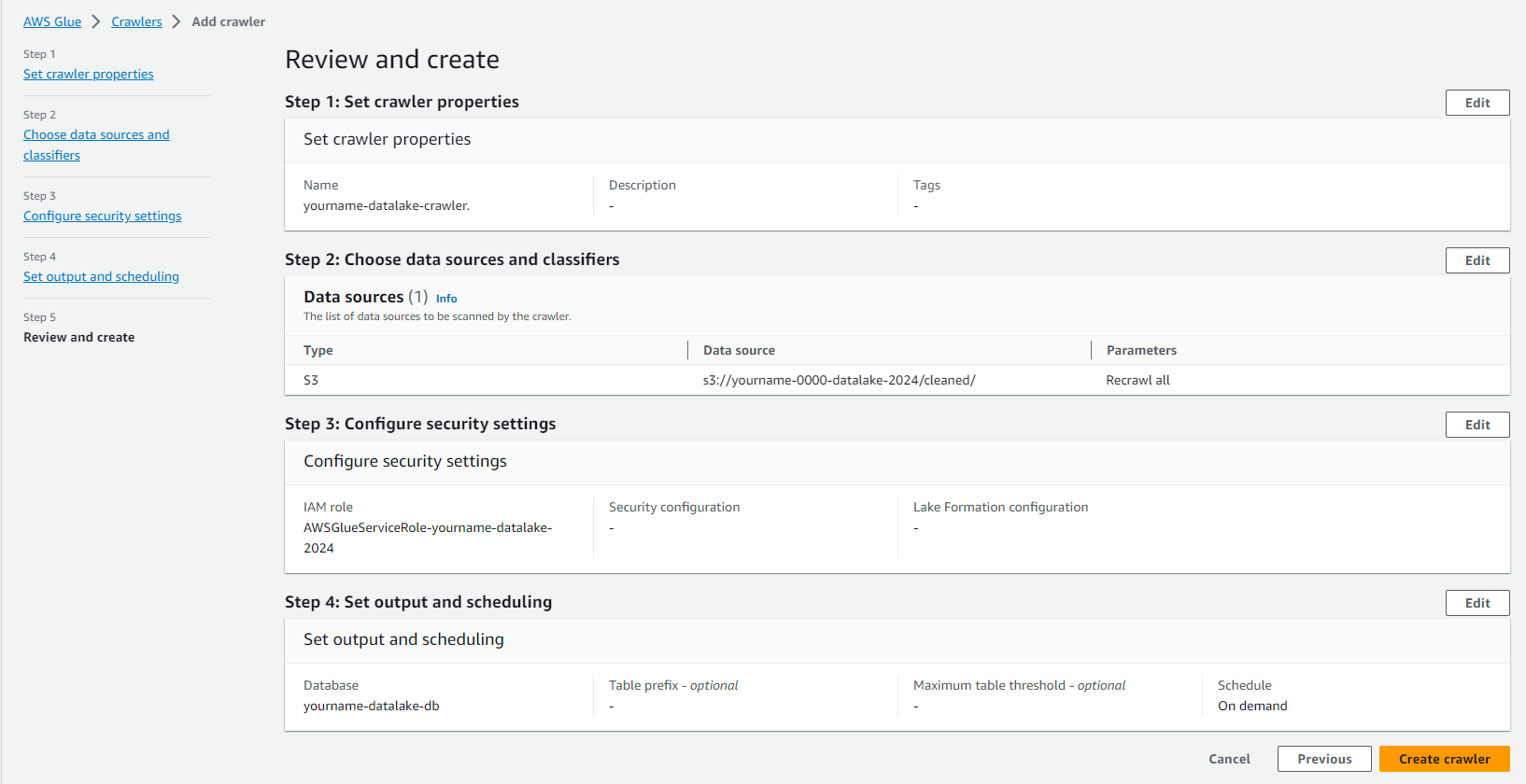
- Click Finish để tiến hành tạo Crawler.
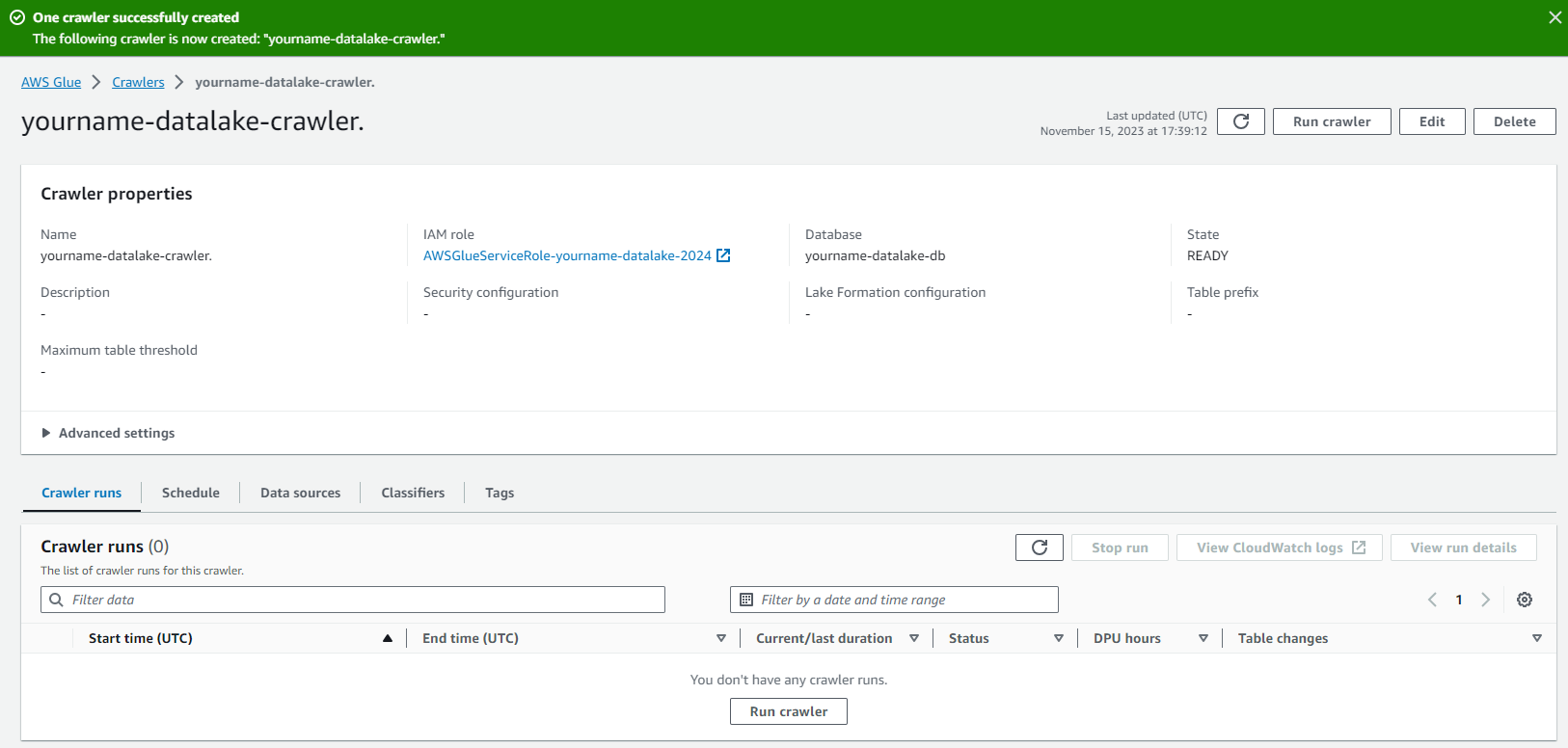
- Click chọn yourname-datalake-crawler.
- Click Run crawler.
- Kiểm tra Crawler chạy thành công như hình dưới.
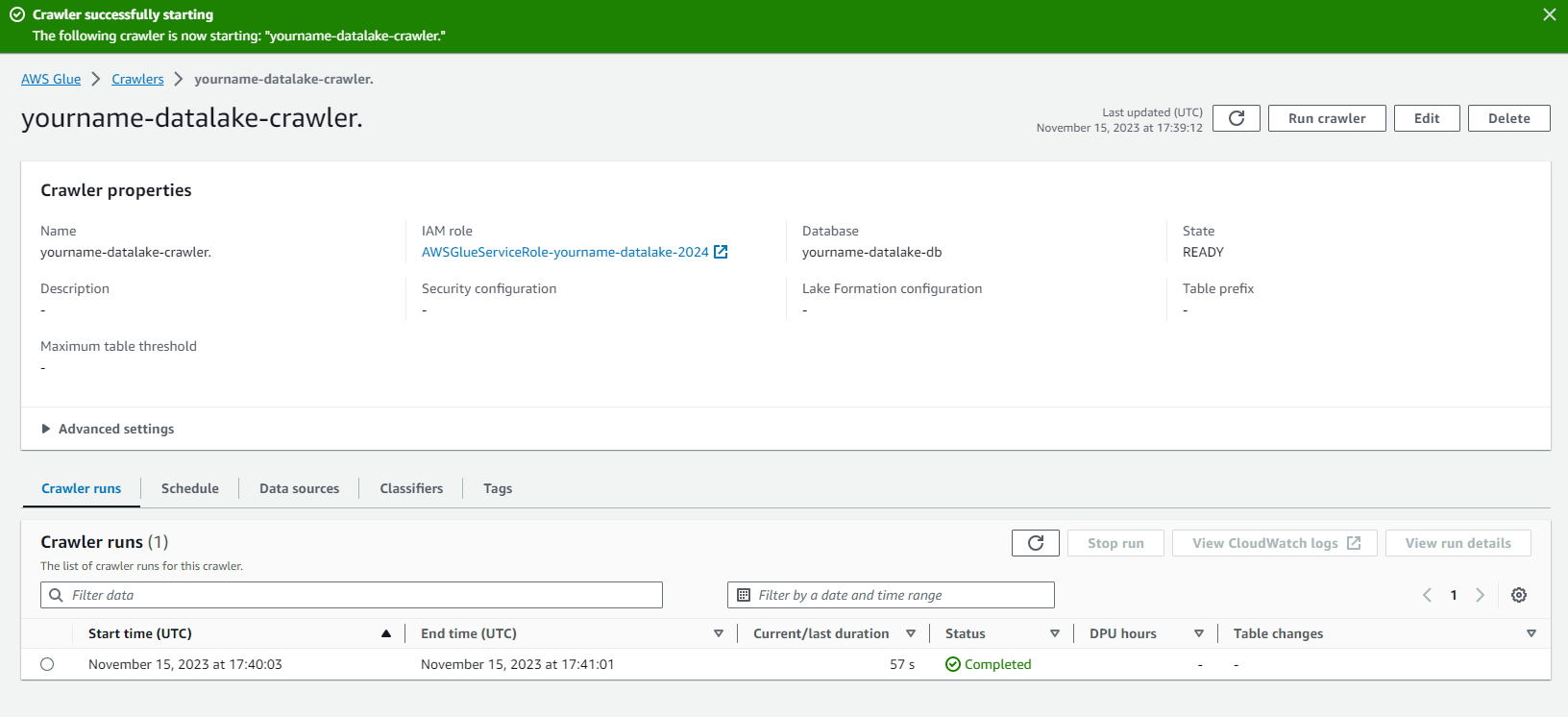
Ở bước này chúng ta đã tạo Crawler job để khám phá dữ liệu và lưu thông tin metadata vào Glue data catalog.Trong bước tiếp theo chúng ta sẽ tạo job để chuyển dữ liệu của chúng ta từ dạng CSV sang dạng Parquet.