Data Profiling
Data Profiling
Khi bạn làm việc trên một dự án, DataBrew sẽ hiển thị các thống kê như số hàng trong dataset và sự phân bố các giá trị duy nhất trong mỗi cột. Các số liệu thống kê này, và nhiều số liệu khác, đại diện cho một profile của mẫu. Khi bạn thực hiện chạy job data profile, DataBrew sẽ tạo một báo cáo được gọi là data profile (hồ sơ dữ liệu). Bạn có thể tạo hồ sơ dữ liệu cho bất kỳ dataset nào bằng cách chạy job data profile.
- Click vào Profile tab trong giao diện Projects.
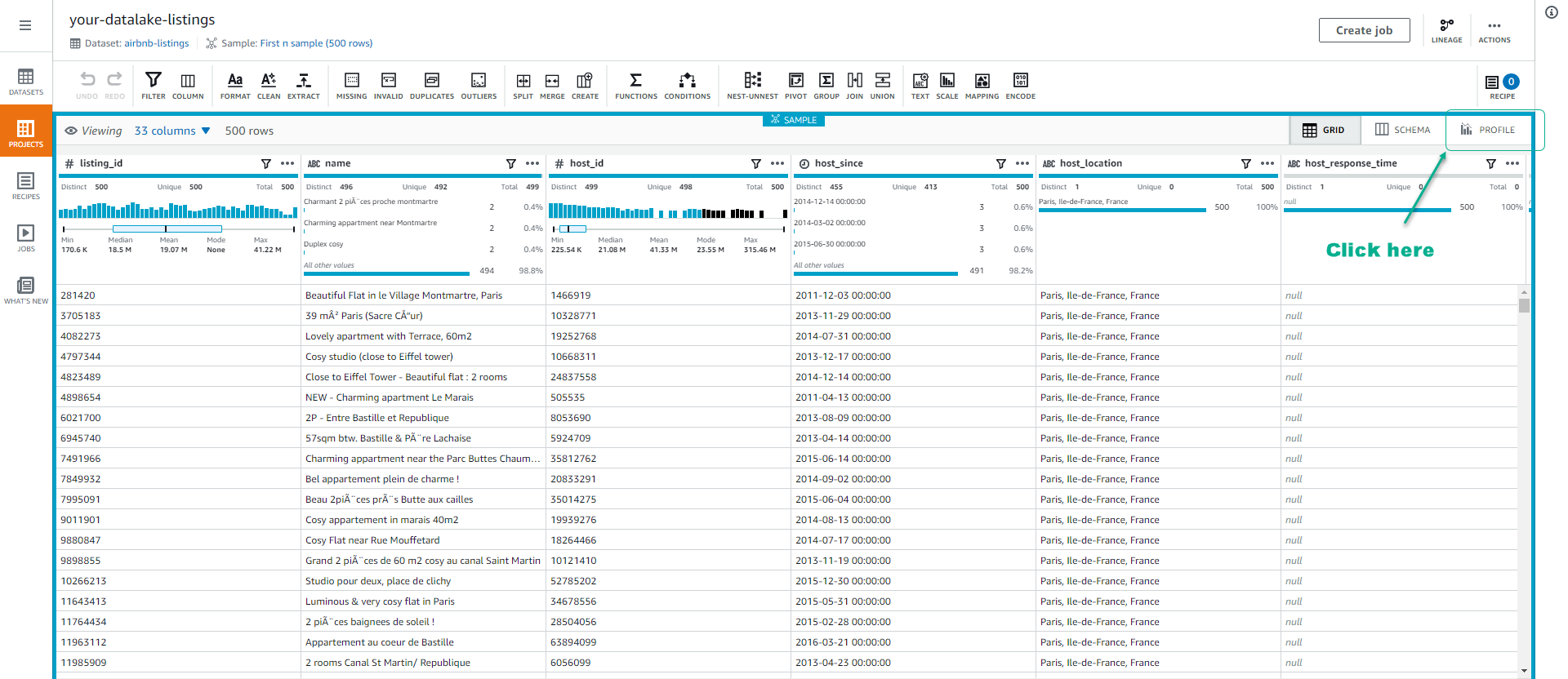
- Click Run data profile.
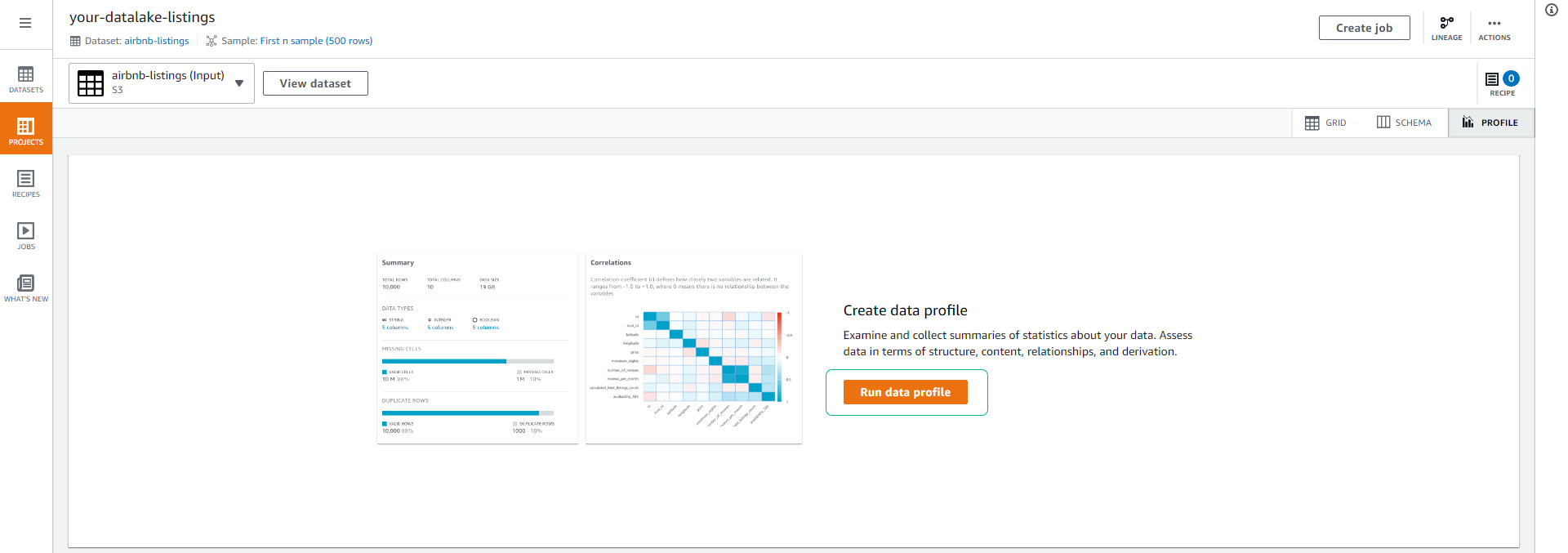
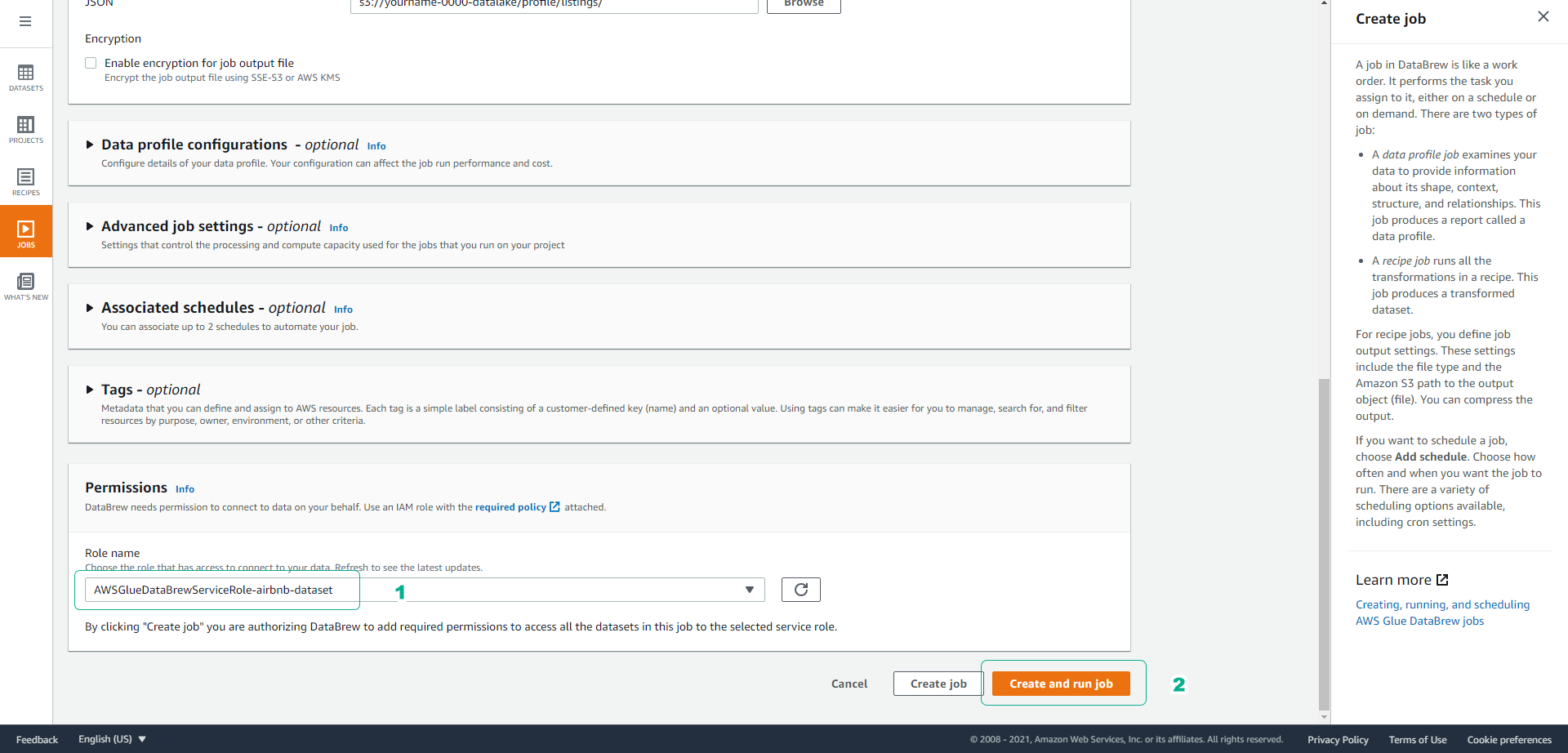
- Tại trang Create job chúng ta giữ nguyên các cấu hình tên mặc định.
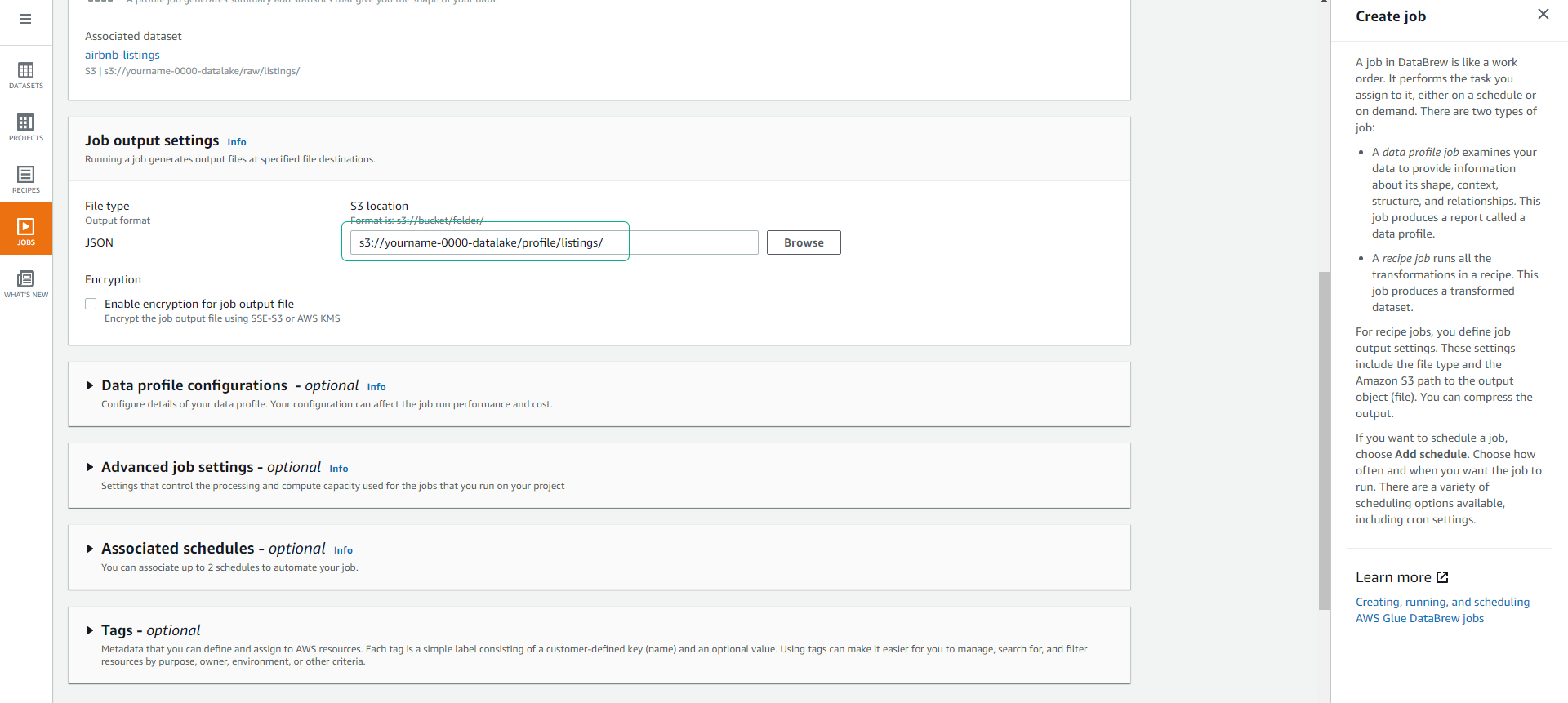
- Kéo màn hình xuống dưới, tại mục Job output settings chọn đường dẫn S3 s3://yourname-0000-datalake/profile/listings/.
- Kéo màn hình xuống dưới, tại mục Permissions chọn Role AWSGlueDataBrewServiceRole-airbnb-dataset chúng ta đã tạo trước đó.
- Click Create and run job.
- Sẽ mất vài phút để job data profile hoàn tất.
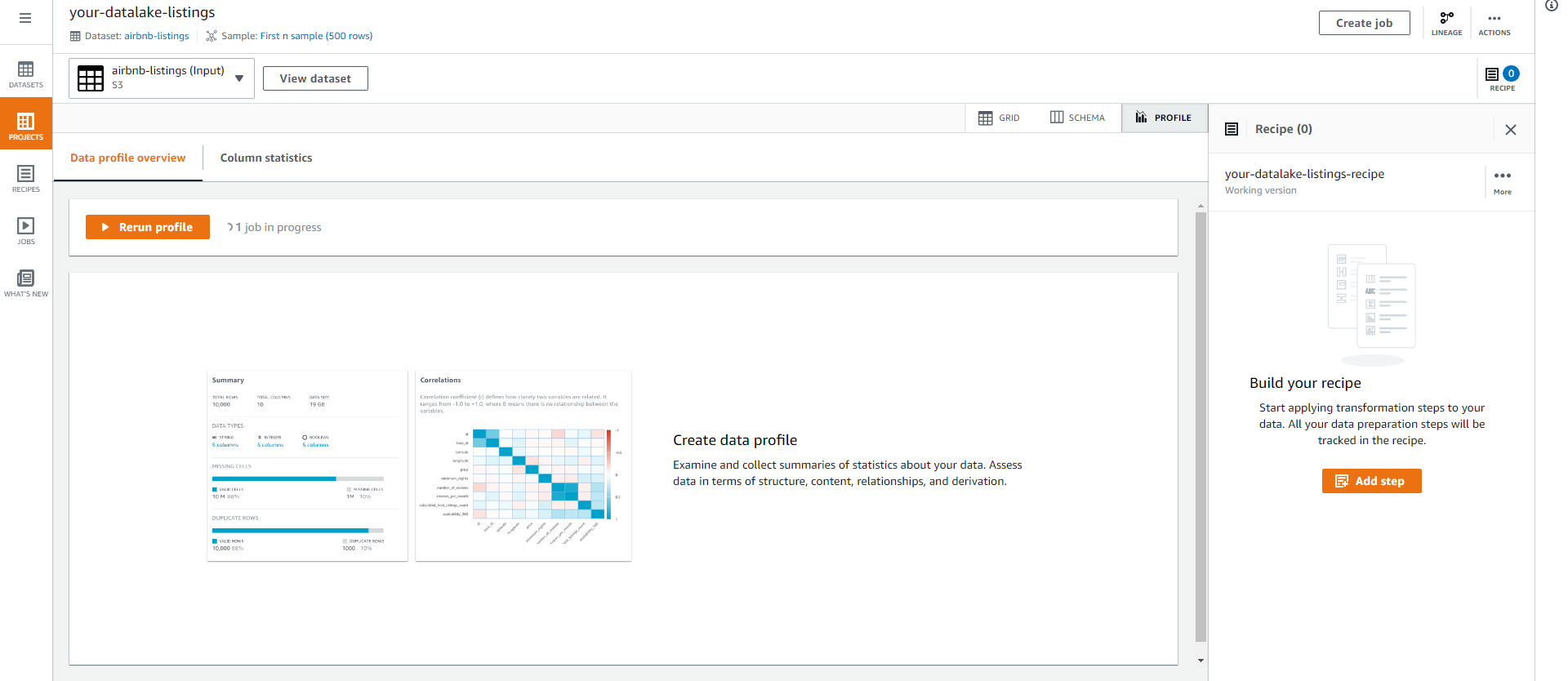
View Dataset Profile
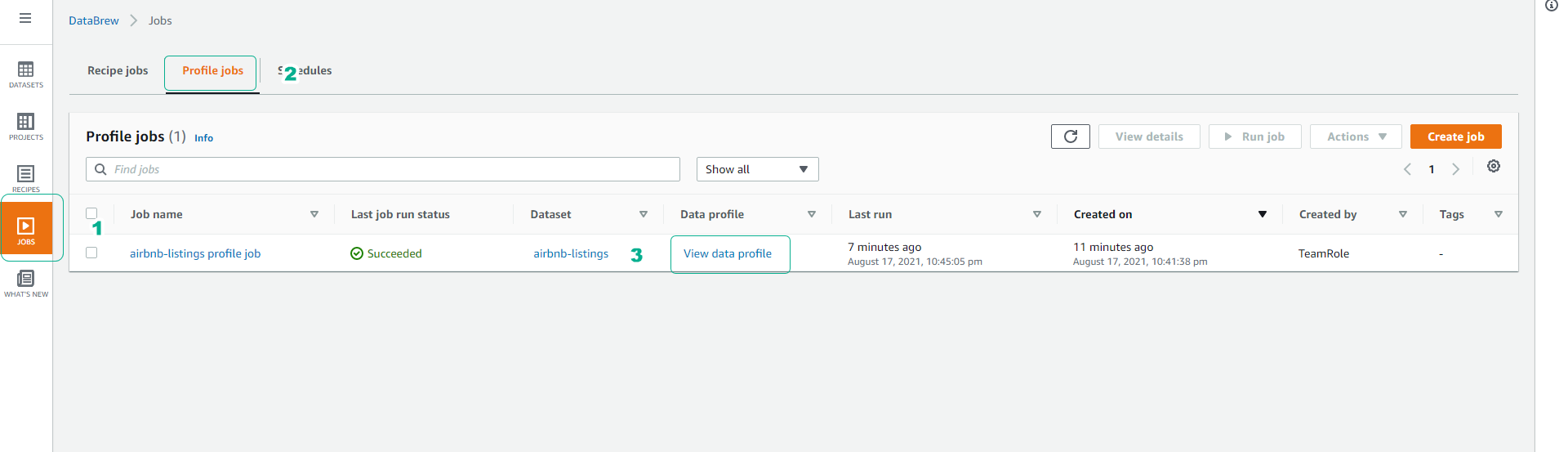
- Click vào menu Jobs
- Click tab Profile jobs để xem các job data profile.
- Nếu job chạy thành công như hình dưới , click View data profile.
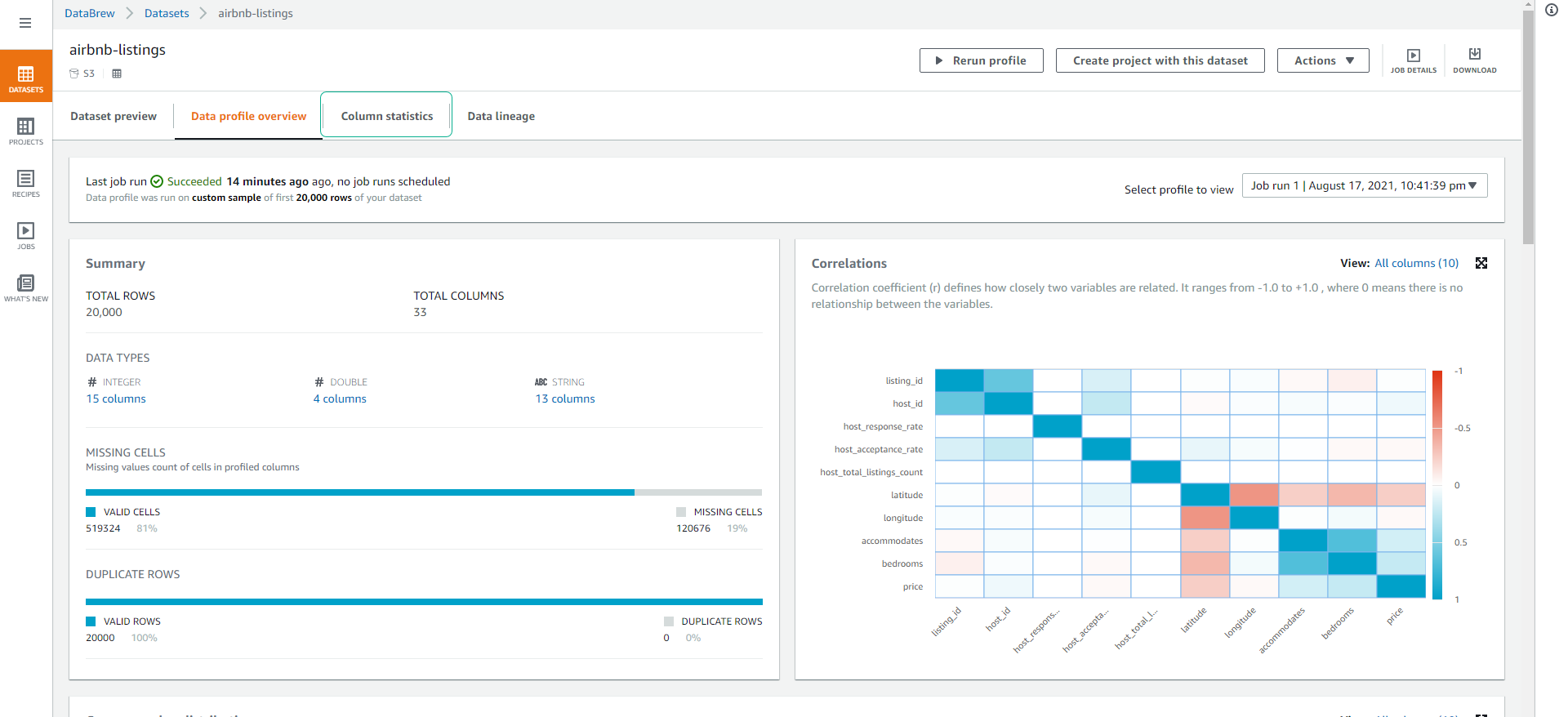
- Chúng ta sẽ xem được thông tin tổng quan về số cột, loại dữ liệu, các giá trị bị thiếu hoặc trùng lắp, cũng như mối tương quan giữa các thuộc tính trong dataset của chúng ta.
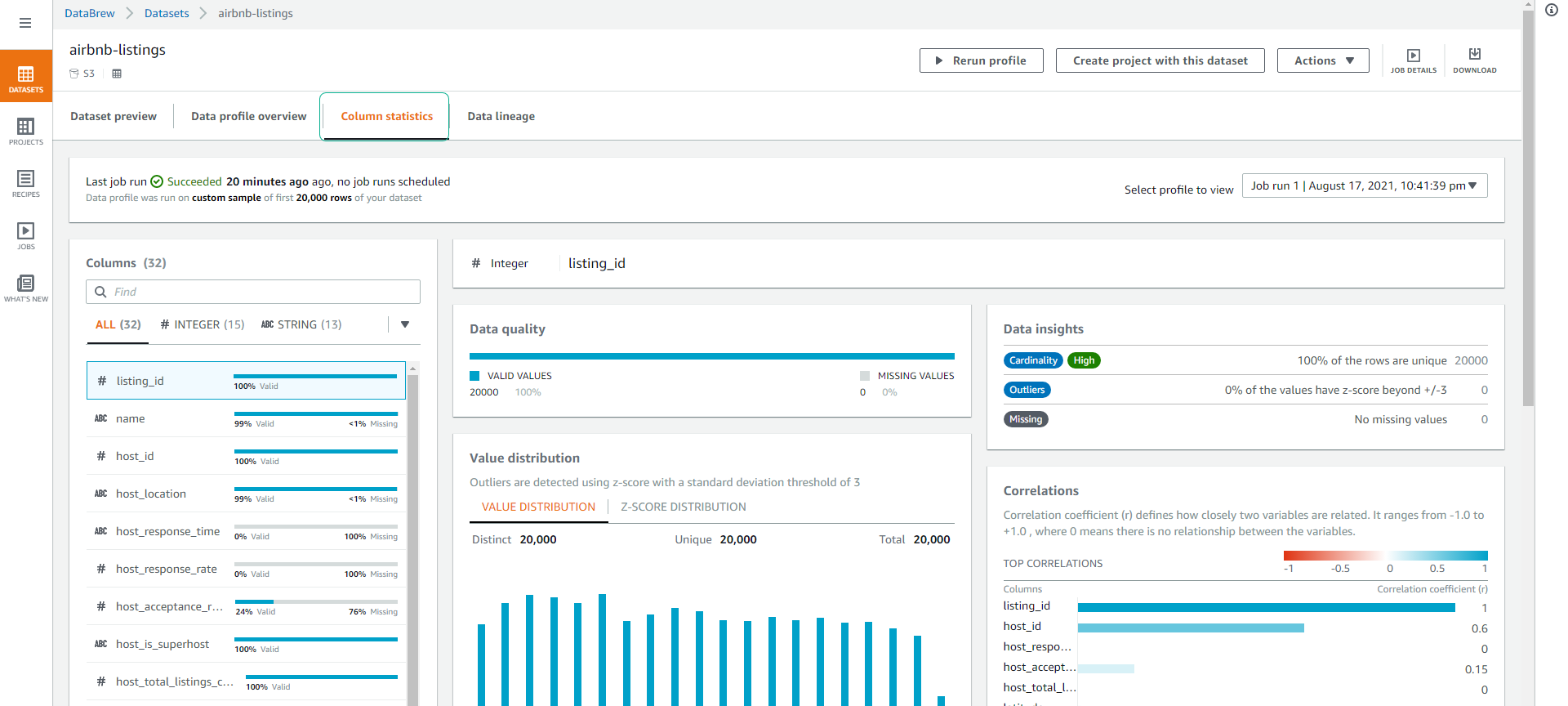
- Click tab Column statistics tại đây bạn có thể đi sâu hơn vào từng cột, kiểm tra chất lượng dữ liệu và sự Phân phối giá trị. Điều này rất hữu ích để tìm các cột có số lượng dữ liệu ít bị trùng (cardinality high nghĩa là dữ liệu ít trùng lắp), giá trị Min, Max và Trung bình.
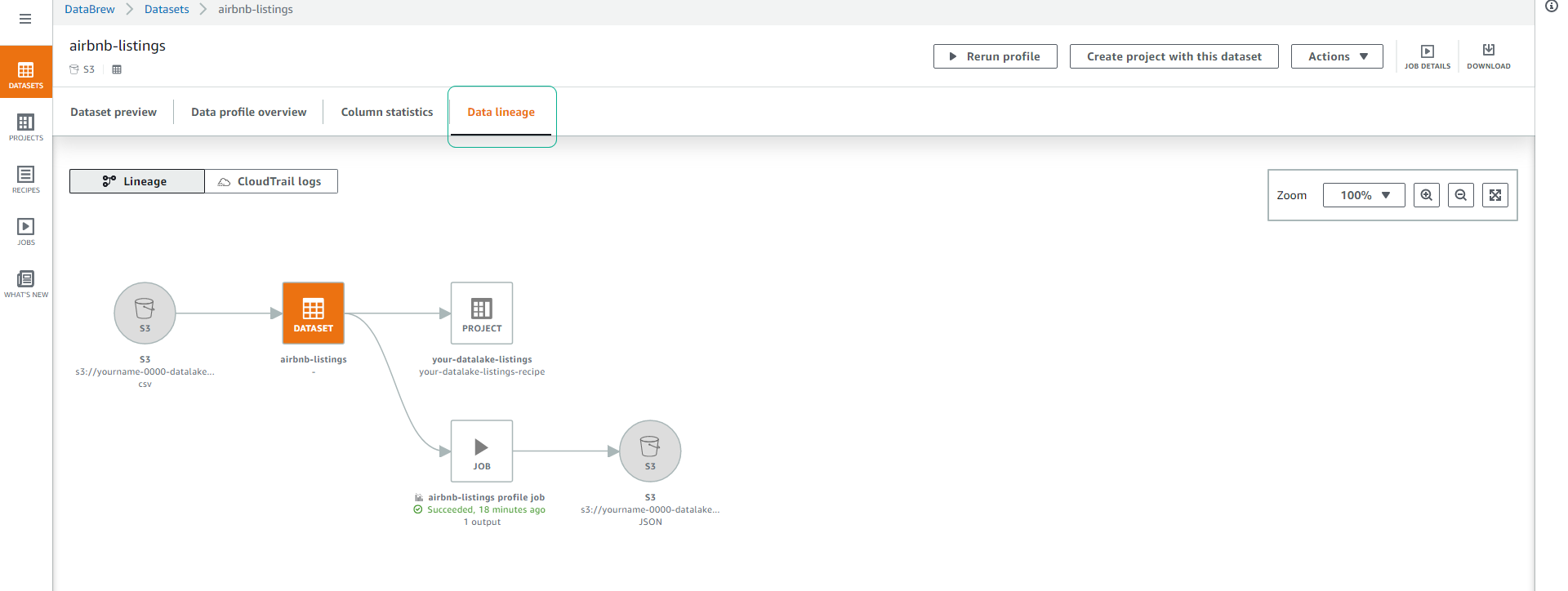
- Click tab Data lineage, chế độ xem cho chúng ta biết dòng chảy của data qua các giai đoạn khác nhau. Chúng ta có thể thấy dữ liệu gốc cũng như các job tác động lên dataset và nơi data được lưu trữ.
Bước tiêp theo chúng ta sẽ thực hiện tạo clean (làm sạch) và transform ( chuyển đổi dữ liệu ).